A data backup strategy is intended to help ensure you’re prepared in case of a severe outage or disaster. Floods, fires, blackouts, malware, cyberattacks and natural disasters are the ones that worry IT administrators most, but what about a leak in the wrong place in your data center roof? What about human error resulting in a corrupted database?
The problem is that, although disasters come in all shapes and sizes, they have one thing in common: they always catch you less prepared than you want to be.
To be prepared in advance, it’s important to be able to answer the following questions:
- Does your organization have a data backup strategy in place?
- What risks does it cover?
- Which goals does it seek to accomplish?
- Have your business stakeholders weighed in on it?
- Have you documented it?
- Have you tested it?
This blog post describes a seven-step plan you can use to inform your organization’s data backup strategy, from initial assessment through ongoing testing.
1. Know your risks
Where are your weakest links? If they break, how will your business be vulnerable?
- Naturally, site-wide disasters are the ones that grab headlines and cause the most concern. An earthquake, flood or tornado doesn’t care how expansive your site is, because it will find you and cause an outage.
- Platform failures trim the incident down to a failure of one element inside your infrastructure, but they include a knock-on effect due to unseen relationships among your technology components.
- Application issues can arise from a seemingly benign change like a patch. If you apply a security update and it contains a bug, you may have to roll back to your last-known good configuration. Controls exist to ensure you understand the risk associated with any change.
- Data loss is top of mind for most IT admins now in the context of ransomware actors. The first risk is that they demand ransom for the data they steal from you and the second risk is that they may also encrypt the data in your storage. For good measure, they’re going after your backups to delete those as well.
- The human factor runs from inadvertent deletion stemming from everyday human error all the way to The Revenge of the Disgruntled Insider and the mischief of nation-state actors.
Risk assessment plays a role here. You can make the mistake of assuming you know your entire IT inventory, but trends like virtual machine (VM) sprawl and shadow IT put much of that in doubt. It’s more prudent to automate your inventory process to ensure you’re not leaving things out.
It may seem like a stretch to occasionally inspect the air conditioning in your data center, the pipes under the floor and what your neighboring businesses are up to. But from the perspective of physical plant, it’s better than being caught completely off guard by an incident. And within your data backup strategy, make room for disaster recovery plans suited to each data center. For example, your data center in Florida has a different risk profile from your data center in Arizona, so take advantage of your distributed data by spreading the risk around.
Your SaaS providers should be able to tell you what they’ve put in place to mitigate risk in their infrastructure. Their risk is part of your risk assessment, so be sure to take it into account.
Here is an example of an IT inventory, risk assessment and risk classification for the data center of a hypothetical enterprise:
| Location | Server/VM | OS and hypervisor | Application | IP address | Disk allocated | Disk used | Dependencies |
| SFO-1 | Orcl-001 | RHEL 7.8 | Oracle 13g | 10.10.10.1 | 5 TB | 1 TB | |
| AD-001 | Win 2016 | AD Domain Controller | 10.10.10.2 | 20 TB | 7 TB | ||
| M365 | Cloud Service | Mail, OneDrive. | 300 TB | MSF | |||
| MOSS-011 | Win 2019 | SharePoint 2019 | 10.10.10.4 | 10 TB | 8 TB | SQL-01, SQL-02 | |
| SQL-001 | Win 2019 | SQL Server 2019 | 10.10.10.5 | 5 TB | 3 TB | ||
| SQL-002 | Win 2019 | SQL Server 2019 | 10.10.10.6 | 5 TB | 2 TB | ||
| SQL-003 | Win 2019 | SQL Server 2019 | 10.10.10.7 | 5 TB | 2 TB | ||
| SQL-004 | Win 2019 | SQL Server 2019 | 10.10.10.8 | STB | 2 TB | ||
| AD-002 | Win 2016 | AD Domain Secondary | 10.10.10.9 | 3 TB | 1TB | AD-001 |
| Location | Assets | Threat (internal and external) | Probability | Impact |
| SFO-01 | Orcl-001, SQL-001, SQL-002,SQL-003, SQL-004, SQL-005, FLS-001, AD-001, AD-002 | Natural disaster - Earthquake | Low | High |
| Network failure | Medium | Medium | ||
| Power failure | Hight | High |
| Class | Description |
| Low impact | All data and systems that are needed to achieve the business' strategic objectives but does not need to be immediately restored for the business to continue to operate. |
| Moderate impact | All data and systems that are important to the achieving business objectives. The business can operate but in a diminished state. |
| High impact | All data and systems that are critical to the business operations. Business comes to halt without the associated services. |
Clearly defined are the assets, the levels of risk and the potential for business impact in the event of a disaster or outage.
2. Know your data
If you don’t know your data, the odds are that you’ll end up paying to blindly back up data you don’t need to keep around.
Not all data in the business is equally valuable. In a data backup strategy, that translates into several important dimensions:
- Money — The more data you have, the more you’ll pay to store it somewhere.
- Time — The more data you back up, the longer it will take to restore when the time comes.
- Technology — Different backup storage options are better suited to different types of data.
The way you think about the technology dimension can make a big difference in your money and time dimensions. Consider these types of data:
- Static — Old data that does not change over time. That doesn’t mean that it’s unimportant; nobody would argue that, for example, your company’s articles of incorporation are unimportant. But it’s been ages since anyone retrieved them, let alone modified them.
- Business-vital — Data that is essential to a business, such as accounting records and strategy documents. Without them, you cannot function.
- Mission-critical — If this data is lost or unavailable, even for short periods of time, the business will sustain damage. For this you want very tight recovery point options so that you lose less data and have less to recover in case of disaster.
Of course, that’s an IT perspective. When you ask line-of-business managers how critical their data is and which data they would need to recover quickly after a disaster, they tell you, “Everything.” And when you’re in IT, your first-round answer is, “Okay. We’ll do it.” But after you’ve had a similar conversation with managers in Marketing, Operations, Engineering, Sales and Support, you present them with an unaffordable cost estimate. So, the second-round conversation starts with “We cannot afford to do everything. So now tell me which data truly is mission-critical. I can back it up and store it with expensive technologies, then use less-expensive data protection technologies for the rest.”
Why does this need to be a two-pass process? Because the managers know their business, but they don’t know their data. That’s why this step is important. In IT, you know that it doesn’t make sense to use the same technology for mission-critical data that you use for static data. The exposure and risk are different because the data is used differently. So different backup and storage technologies are called for.
Mind you, not every organization does it that way. Some IT groups don’t work like that. They set a service level agreement (SLA) for the business and say, “This is the backup and storage technology we use. We can afford to keep the data for X months, no matter what it is. After that, we move it somewhere else or delete it.”
Or you may group your applications by importance. If, for example, your customer transaction database has a high rate of churn, do you need to keep snapshots of it for a year? Probably not, because it will have changed so much in a year as to be useless.
3. Know your goals
The one main goal of your data backup strategy, of course, is to recover data in case of disaster. As you break that down and think about needing to recover data, you evaluate the importance of each data set. Why? Because the type of backup and recovery mechanism you’ll use is a function of that importance and how long you can operate without the data set.
In the “Know your data” step, you had conversations with business managers about backing up. In this step you have conversations about recovery, downtime and SLAs. The managers will say, “I know what you can back up. How quickly can you recover it?” And it’s up to you to tell them what you can recover and in what time frame.
The conversation revolves around questions such as these:
- What kind of outage might happen?
- How long is the application likely to be offline?
- For how long will we be unable to work?
- For how long will customers be unable to use our systems? What about business partners?
That’s how you start to build an SLA, based on applications, to the rest of the business. You may tell Finance, for example, “Our ERP is a major business application, so we’ll use these techniques to recover it in case of disaster. It will be back up and running for you within x hours.”
IT teams continually work on the basis of SLAs with external service providers like Azure, AWS and Google. In turn, SLAs are just as applicable to the services that IT provides internally.
4. Know your tools
The service levels you agree to depend on your technical capabilities, and you have several options when it comes to recovering data:
- File- and folder-based recovery
- Application-aware recovery; for example, restoring assets like SQL databases in such a way that they are available as soon as the machine is recovered
- Machine image-based snapshot recovery, which has long been popular with virtual machines and can also apply to physical machines
- Deduplication and replication for determining how and where you store your data as part of your data backup strategy
- Single-item recovery and high-speed machine recovery, for when the disaster is limited to, say, losing the CTO’s laptop or deleting a couple of very important email messages
- Cloud data and usage time to recovery, for putting a data set back up into the cloud if it’s been lost. Have you been replicating that data set to different cloud regions, and can you recover it from there? How long will it take to point your services at the replicated data set?
You face a cost-versus-risk axiom in data recovery: The more effective the recovery mechanism, the more it will cost you. And the cheaper it gets, the longer it takes to recover the data. With that in mind, here’s an example of flow for your data backup strategy:
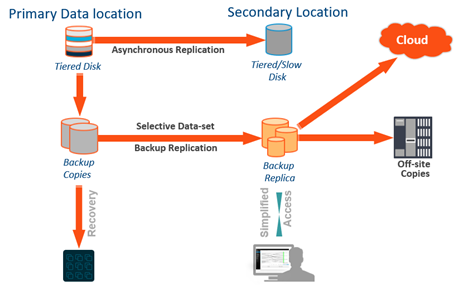
At the top level, you take snapshots of data that’s stored on the primary disk, in case you need to recover in bulk. But snapshots are not so useful in case of complete failure of the disk system, so consider asynchronous replication to a secondary location. That’s a useful technique for recovering large amounts of data, but it usually means buying secondary storage and primary storage from the same manufacturer. You reduce risk, but it’s more expensive.
The next level down contains your backup sets, where the 3-2-1 rule applies: Maintain 3 copies of your data in 2 different media formats, then store 1 of them at a remote site. So, your three copies of data are the primary, a secondary copy and a third copy in another location. Then, your two formats could be in the cloud or on tape. But in any event, one of them is off site. You could then use any of those backups for recovery, depending on the age and size of the data.
In short:
- You want the snapshots for the big, quick, instant recovery of large amounts of data.
- The backup copies are your safety net. If your storage system fails, you can recover everything from backups.
- The secondary copy is effective against ransomware. Store it somewhere else, or on tapes separated from your network by an air gap.
As you formulate your data backup strategy, you should weigh heavily the threat of ransomware. Particularly worrisome is the trend toward double extortion ransomware attacks, which not only encrypt all your data but also steal it and threaten to publish it. Your backup, being a copy of your entire corporate data set, is an appealing target for ransomware. So your data backup strategy has to ensure that: 1) no attack leaves you without access to your backups; and 2) if your backups are exfiltrated, they are useless.
In defending your backup data against ransomware, data immutability is a valuable feature. An immutable backup is a set of backup data that, once written, cannot be changed in any way — not even ransomware can change it. The ideal of immutable backups is air-gapped data storage that is isolated from the rest of your network. An example is performing an encrypted backup to tape, then removing the tape from the drive until it’s needed for recovery. That way, the backup data is protected and cannot be removed or edited.
You have plenty of options beyond the single backup software/recovery solution. You can tailor your recovery technologies from the very edge, where the data is first written, all the way through to backups that meet different requirements.
5. Build an offsite data backup strategy
Part of that 3-2-1 rule is storing your data somewhere off site and secure. Think of your second-site options in terms of temperature:
- Cold, like tape storage. Again, tape is inexpensive, and a valuable defense against ransomware, but it comes with long recovery times.
- Warm, like secondary backup onto a service provider’s disk storage.
- Hot, like replicating an entire data center. While it’s expensive, it allows you to fail over with everything already in place and running.
Again, your decisions about backup systems are driven by how the people who own the data want you to recover it for them. In other words, to what extent do you duplicate your primary solution set? How far down do you scale what you have in your data center?
Note that cloud backup is becoming increasingly viable for off-site storage. You can perform simple recovery from cloud storage if things go horribly wrong, or you can subscribe to disaster recovery as a service (DRaaS). The cloud offers readiness with a big cost advantage: you don’t have to pay for infrastructure until you start using it. Recovery is slower than if you had duplicated your entire solution set, but it’s quicker than having to rebuild everything from scratch, given lead times on hardware.
Your data backup strategy is about more than just retaining and securing data. It’s also a matter of being ready with the recovery technology best suited to the type of risks and data described above. The conversations you have with your business managers inform the recovery technologies you invest in for data readiness.
6. Document your plan
To cap off all of the effort that you put into planning for recovery, it’s important to document it. Your written recovery plan spells out your data backup strategy, how you back up, how long you keep which kinds of data and your SLAs back to the business.
IT administrators often get stuck here because they spend years thinking, “I back up our data,” but they don’t think any further. As described above, the recovery piece is what matters most to the business, so that’s where your plan must focus.
The chart below illustrates the difference between having a documented plan, in the form of a data backup strategy, and not having one:
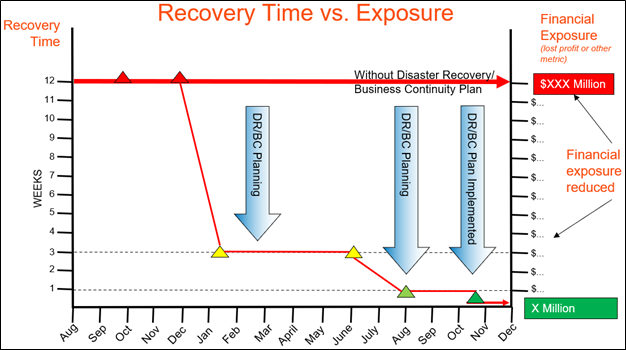
Without a documented disaster recovery/business continuity plan in place, you could expect to spend this entire time frame at the level of risk along the heavy, red line. That is, you’d be facing long recovery time and correspondingly high financial exposure.
If you hadn’t planned an order for recovering applications and data — including the process and time to recover them — then it could take you days or weeks to recover. You’d be lost without an understanding of system dependencies. You’d run from pillar to post trying to get everything working, without regard to the right order and to the higher-level priorities of the business. Without a plan, you’ll spend more money and more time, with collateral damage to things like your profit and reputation.
With a documented plan in place, on the other hand, your risk and recovery time would start to fall, as shown in the thin, red line. More planning would position you closer to the lower-right corner. Your plan would enable you to recover applications and data in the order in which the business needs them. Consequently, you would spend less money and time recovering from disaster, with lower financial exposure and less likelihood of reputational damage.
7. Test your plan
It’s important to point out that the biggest mistake companies make is neglecting to test, or challenge, their data backup strategy.
They trust their backup solution implicitly, but, like any other kind of software, it can have bugs or do unexpected things. For that matter, they may have configured it incorrectly. They say, “It backs up every day of every week and it runs smoothly — no error messages.” Then, when they have an outage and try to restore, there’s nothing there.
So test to make sure you can restore data and use it as well. Have you tried to mount a database so you know whether it’s corrupted? You might have a file back, but can you use it?
Testing always seems like too much work, but it’s always less work (under less stress) than scrambling to recover with a backup set that is less perfect than you thought. The following table summarizes four levels of testing, with appropriate frequency:
| Class | Description | Frequency |
| Walk-thru exercise | Review the layout or contents of your DR plan | As often as necessary to familiarize response teams and individuals with a documented plan or changes to a plan |
| Tabletop exercise | Using a scenario, discuss the response and recovery activities of a documented plan | At least 4 times per year, or any time a change is made to the business or IT operating environment |
| Component exercise | Physically exercise a component of a DR plan (e.g., testing automated communications services or work-from-home capabilities together with IT or partner capabilities) | At least twice per year, or when a change is made to the business or IT operating environment |
| Full-scale simulation | Using a scenario, carry out the response and recovery activities of a DR plan for the entire organization | At least once or twice per year, or when a change is made to the business or IT operating environment |
Consider automating some testing — the way Engineering does — to add coverage. You can perform automated recovery as well.
Protect all your systems, applications and data.
Finally, build your data backup strategy into the IT planning cycle. That means that everything you put in place for your business to use has a relevant backup that meets the restoration requirements. Remember that the goal of backing up is to restore data and it’s part of the whole IT planning cycle.
Conclusion
The moral of the foregoing seven steps is that, if you can’t back it up and recover it, then you shouldn’t put it into production. To do so is to put your company at risk.
When managers in the business want to introduce a new technology, application or data set, you’ll have the same conversations with them about risks, data and goals. Set a policy of not deploying anything new until you can protect it properly and put it into the recovery plan.
Once that plan is in place, and you’ve documented and tested it, you can then say that your data backup strategy is sound, and that your applications and data are protected and can be restored according to your predicted SLAs.