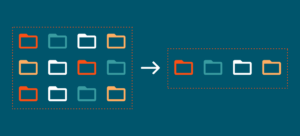
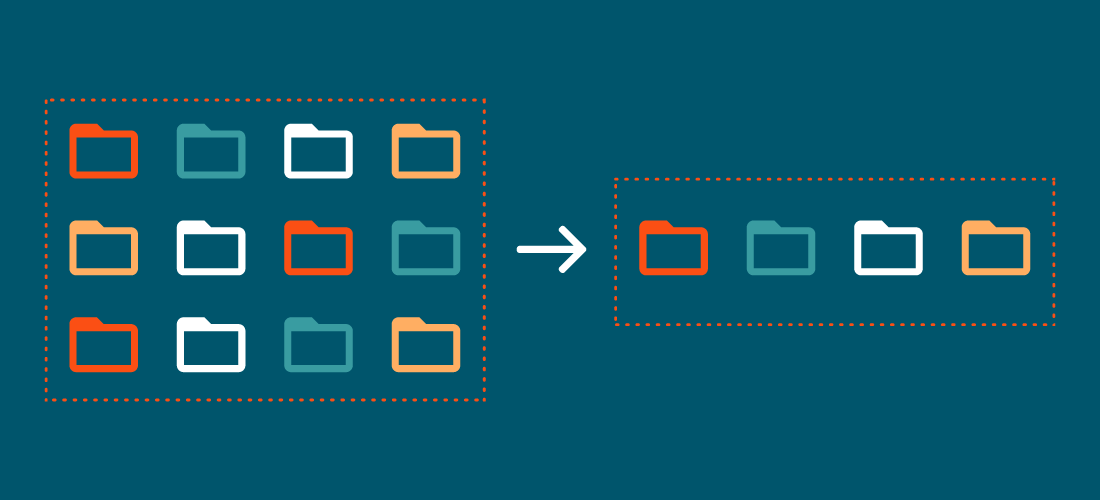
Data deduplication is the process of identifying and eliminating blocks of duplicated data, such as in a data backup set. It involves examining data within files and storing only the blocks that have changed since the previous backup operation.
How does data deduplication work?
The data deduplication process is based on eliminating redundancy in data. Here’s a greatly simplified example: Consider an ordinary file, like the draft of this blog post. Suppose I create the first draft on Monday — a 100 kilobyte (KB) file — and save it to my local drive. Later that day, my backup software sees the new file and backs it up over the network to a deduplicating storage solution, where it takes up 100 KB. On Tuesday, I open the file on my local drive, append a few sentences and save it: now it’s a 101 KB file. Late Tuesday, my backup software sees that the file has changed. The file is then backed up again: this time it’s 101 KB. When the new data arrives at the deduplicating storage solution, it finds the similar data from Monday (100 KB), matches it with Monday’s 100 KB, substitutes pointers to the original data and stores the 1 KB that has changed from Monday to Tuesday. Data deduplication identifies and stores only that 1 KB of new data along with pointers to the first occurrence of the original 100 KB of data.
Why is data deduplication important?
Eliminating duplicated data is important because blocks of storage, whether in the cloud or on-premises, cost money.
Here’s an example that describes the impact of not deduplicating (or choosing the wrong deduplication technology). Suppose you’re responsible for protecting a data set 100 terabytes in size, and that you retain each weekly backup for 12 weeks. By the time your backups start aging off, your 100 TB data set will take up 1.2 petabytes (12 x 100 TB) of storage.
Do you want to be the one to explain to Finance why it costs 1.2 petabytes’ worth of space to protect 100 TB of data? Of course not.
It gets worse. Blocks of storage are not the only resources that are sensitive to waste from redundant data.
- Network — When blocks of redundant data are needlessly sent from devices to backup servers to storage, network paths become saturated at multiple points, with no corresponding increase in data protection.
- Devices — Any device along the backup path, whether it hosts the files or merely passes them through, must squander processor cycles and memory on the redundant data.
- Time — As companies count on having their applications and data available around the clock, any performance hit from backing up is unwelcome. That’s why IT admins plan for a backup window in which the impact of the backup on system performance will be minimal — usually at night. Redundant data takes up precious time in that window.
Since every block of storage taken up with redundant data amounts to wasted money, storage administrators rely on data deduplication to avoid storing the same data more than once. Over time, the combination of data deduplication and compression can reduce storage requirements by 90 percent or more.
Benefits of data deduplication
Global source-side data deduplication can simplify and accelerate overall backup and recovery in many ways. Whether you are performing data backup and recovery for physical or virtual environments, your storage footprint and costs will be significantly reduced.
By eliminating redundant data at the source, you can also reduce network traffic and get better throughput across your LAN and WAN to address ever-shortening backup windows. With optimized backups, you’ll be able to backup and replicate to the cloud for disaster recovery and data archiving.
Overall, data deduplication has the ability to make whatever backup software you use better, faster, and more secure while reducing storage costs by 90% or more
Data deduplication offers numerous advantages that directly influence the efficiency of your digital infrastructure and resource utilization:
- Establishes backup capacity by minimizing redundancy, particularly in full backups.
- Facilitates continuous data validation, ensuring problems are identified beyond merely storing backup data, which only reveals issues during recovery.
- Enhances data recovery by providing accuracy, speed, and reliability.
- Supports optimal disaster recovery for backup data due to deduplication’s excellent capacity optimization capability.
- Occupies a smaller data footprint, optimizing storage space.
- Utilizes less bandwidth during data replication, remote backups, and disaster recovery.
- Allows longer retention periods for data.
- Achieves reduced tape backups with faster recovery time targets.
An example of data deduplication
An ordinary email system could include 100 duplicates of a 1-megabyte (MB) file attachment. When the email platform is backed up or archived, all 100 duplicates are preserved, consuming 100 MB of storage space. Through data deduplication, only a single instance of the attachment is retained, and each subsequent duplicate is linked to the initially saved copy.
In this example, the storage requirement decreases from 100 MB to 1 MB.
What is the difference between deduplication and compression?
Deduplication and compression have the same goal: to reduce the quantity of backup data stored.
Deduplication uses algorithms to identify data that matches already stored data. If the algorithms find duplicated data, they replace it with a pointer to the already stored data. Then, they send only the unique data to be stored.
Data deduplication is usually represented in ratios; for instance, a 10:1 reduction ratio means that you’re reducing the storage capacity requirements by 90%.
Data compression algorithms, on the other hand, do not take already stored data into account. They ingest a specified file or set of files and compact them by replacing any repeated sequences with tokens and removing unneeded fillers and spaces in the data.
Although the two technologies operate differently and have different use cases, they are complementary. Data deduplication software often includes a built-in compression utility.
What is a deduplication process?
At the heart of the deduplication process is the technique used by the algorithm to scan the data. The goal is to distinguish the unique chunks — those that are new or changed since the last backup — from the matched (or duplicated) chunks — those that have already been stored. Once that has been accomplished, the deduplication software knows which chunks to send to storage and which to create a pointer for.
Two of the most common (because successful) approaches are called fixed-block deduplication and variable-block deduplication.
Fixed-block deduplication
Fixed-block deduplication takes a stream of data and slices it into chunks of a fixed size. The algorithm compares the chunks and, if it finds they are the same, it stores a single chunk and keeps a reference for each subsequent match.
Fixed-block works well on some data types that are stored directly on file systems like virtual machines. That’s because they are byte-aligned, with file systems written in, say, 4 KB, 8 KB or 32 KB chunks. But fixed block deduplication does not work well on a mixture of data where those boundaries are not consistent, because the alignment changes as the data in the files change. The first three rows of the figure below, with their chunk boundaries at exactly the same offset, illustrate changes to only a couple of characters. But changing from “Ishmael” to “Ish” or to “Izzy” prevents the algorithm from recognizing the rest of the content. The algorithm then considers all the rest as unique and sends it needlessly to storage.
Data, of course, is anything but consistent, so different data types, block sizes, byte alignments and content are to be expected.

Variable-block deduplication
The alternative, variable-block deduplication, is a way of using a changing data block size to find duplicates.
The data goes through a Rabin fingerprinting algorithm and a chunk is created when a unique set of bytes are found. The data is variable and is calculated over a sliding window. That means the algorithm can identify the same set of bytes of data again and again, no matter where they are in the stream.
In the diagram above, for example, compare the fourth line with the first line. The algorithm can identify the duplicate chunks in “years ago — never mind how long precisely” even though the data is not aligned. Variable-block deduplication is designed for that, but fixed-block deduplication is not.
Furthermore, in variable-block deduplication it does not matter whether changes occur before or after a duplicate chunk in the stream of data. Once the chunk is identified, a hash is generated and stored in the deduplication dictionary. The algorithm will match the hash with the hash from any subsequent occurrences of the data, identify the duplicates and ignore them.
Overall, variable-block deduplication provides more matches in a stream of typical enterprise data, thereby reducing the unique data that has to be stored. The result is significantly lower storage requirements compared to other data deduplication technologies.
Content-aware, variable-block deduplication
An additional refinement to variable-block deduplication is to introduce awareness of the content of the stream itself. A content-aware, variable-block algorithm identifies patterns in the data in spite of the shifting that results from additions or deletions in the data stream. It then aligns the start- and endpoints of the block to duplicate chunks, identifying only the changed chunks as unique. Content-awareness can lower storage requirements even further.
How does data deduplication work in storage?
The other important aspect of data deduplication is the point of implementation. Is it better to deduplicate at the source, where the application or data is hosted? Or at the target, where the backup copy will be stored?
As described above, redundant data affects not only storage but also network traffic, time in the backup window and other devices on the network. The goal is to put the workload of deduplication where it will have the lowest overall impact. In most cases, that is at the source (source-side deduplication). When the algorithm runs on the backup stream at the source server, only unique data needs to be sent over the network. That generates some additional overhead on the source application servers, but far less overall impact than a saturated network path.
Source-side deduplication also benefits the time dimension. With less data moving across the network, you can run more backup jobs in parallel. The result is that you can back up more data in the same backup window or you can shorten the window and return to normal system performance sooner.
Protect all your systems, applications and data.
Besides those implementations in file storage, data deduplication also matters for object storage, which manages data as a file with customized metadata and a unique identifier. Object storage in the cloud has become the model of choice for commercial cloud services like Amazon Simple Storage Service (S3), Microsoft Azure Blob storage and Google Cloud storage. Because the services charge by usage, it behooves you to trim your storage footprint in any way you can. Data deduplication and compression reduce the quantity of backup data stored and, along with cloud tiering, can greatly lower cloud spending.
Is data deduplication safe?
Data deduplication algorithms do not make decisions about which data is important; they decide only which data is redundant.
Nor do they discard data to save on storage. Through the process of rehydration, they are able to completely and reliably reconstitute backed-up data.
Conclusion
Data deduplication is the process of eliminating redundant data from a stream, like a backup. As your storage requirements grow and the need to lower costs becomes more compelling, deduplication methods offer welcome relief. Besides cutting the amount (and cost) of storage space, deduplication can reduce network congestion, consolidate backups and make better use of your precious backup window.


