The availability, accessibility and performance of data are vital to business success. Performance tuning and SQL query optimization are tricky, but necessary practices for database professionals. They require looking at various collections of data using extended events, perfmon, execution plans, statistics, and indexes to name a few. Sometimes, application owners ask to increase system resources (CPU and memory) to improve system performance. However, you might not require these additional resources and they can have a cost associated with them. Sometimes, all that’s required is making minor enhancements to change the query behavior.
In this article, we’ll discuss a few SQL query optimization best practices to apply when writing SQL queries.
SELECT * vs SELECT column list
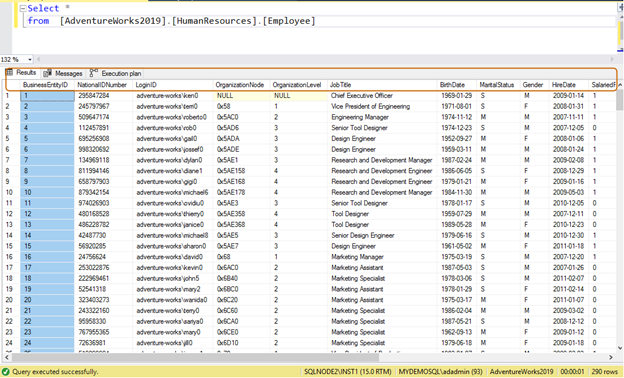
Usually, developers use the SELECT * statement to read data from a table. It reads all of the column’s available data in the table. Suppose a table [AdventureWorks2019].[HumanResources].[Employee] stores data for 290 employees and you have a requirement to retrieve the following information:
- Employee National ID number
- DOB
- Gender
- Hire date
Inefficient query: If you use the SELECT * statement, it returns all the column’s data for all 290 employees.
Select * from [AdventureWorks2019].[HumanResources].[Employee]
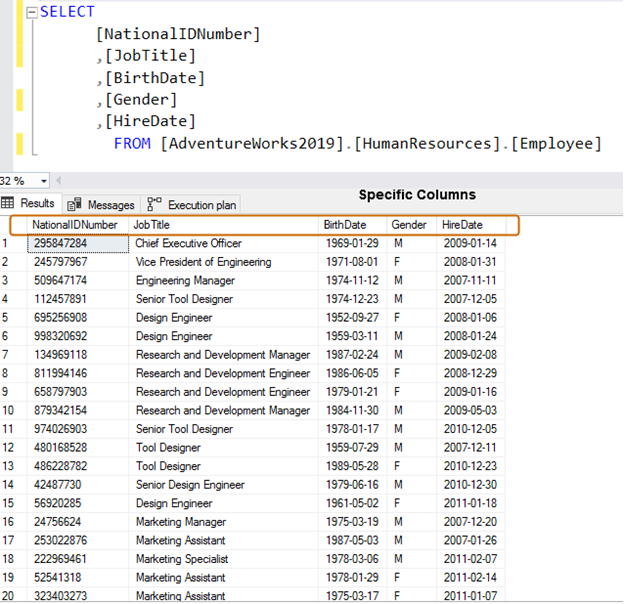
Instead, use specific column names for data retrieval.
SELECT [NationalIDNumber] ,[JobTitle] ,[BirthDate] ,[Gender] ,[HireDate] FROM [AdventureWorks2019].[HumanResources].[Employee]
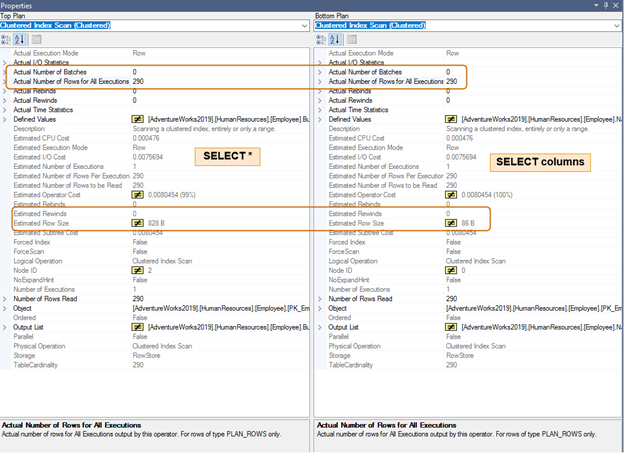
In the below execution plan, note the difference in the estimated row size for the same number of rows. You will notice a difference in CPU and IO for a large number of rows as well.
Use of COUNT() vs. EXISTS
Suppose you want to check if a specific record exists in the SQL table. Usually, we use COUNT (*) to check the record, and it returns the number of records in the output.
However, we can use the IF EXISTS() function for this purpose. For the comparison, I enabled the statistics before executing the queries.
The query for COUNT()
SET STATISTICS IO ON Select count(*) from [AdventureWorks2019].[Sales].[SalesOrderDetail] where [SalesOrderDetailID]=44824 SET STATISTICS IO OFF
The query for IF EXISTS()
SET STATISTICS IO ON IF EXISTS(Select [CarrierTrackingNumber] from [AdventureWorks2019].[Sales].[SalesOrderDetail] where [SalesOrderDetailID]=44824) PRINT 'YES' ELSE PRINT 'NO' SET STATISTICS IO OFF
I used statisticsparser for analyzing the statistics results of both queries. Look at the results below. The query with COUNT(*) has 276 logical reads while the IF EXISTS() has 83 logical reads. You can even get a more significant reduction in logical reads with the IF EXISTS(). Therefore, you should use it to optimize SQL queries for better performance.

Avoid using SQL DISTINCT
Whenever we want unique records from the query, we habitually use the SQL DISTINCT clause. Suppose you joined two tables together, and in the output it returns the duplicate rows. A quick fix is to specify the DISTINCT operator that suppresses the duplicated row.
Let’s look at the simple SELECT statements and compare the execution plans. The only difference between both queries is a DISTINCT operator.
SELECT SalesOrderID FROM Sales.SalesOrderDetail Go SELECT DISTINCT SalesOrderID FROM Sales.SalesOrderDetail Go
With the DISTINCT operator, the query cost is 77%, while the earlier query (without DISTINCT) has only 23% batch cost.
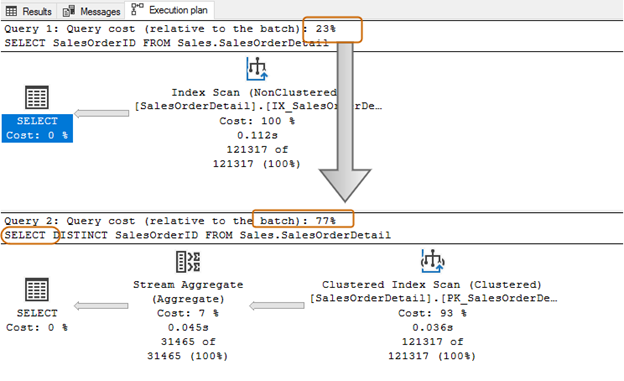
You can use GROUP BY, CTE or a subquery for writing efficient SQL code instead of using DISTINCT for getting distinct values from the result set. Additionally, you can retrieve additional columns for a distinct result set.
SELECT SalesOrderID FROM Sales.SalesOrderDetail Group by SalesOrderID
Wildcards usage in the SQL query
Suppose you want to search for the specific records containing names starting with the specified string. Developers use a wildcard to search for the matching records.
In the below query, it searches for the string Ken in the first name column. This query retrieves the expected results of Kendra and Kenneth. But, it also provides unexpected results as well, for example, Mackenzie and Nkenge.
In the execution plan, you see the index scan and the key lookup for the above query.
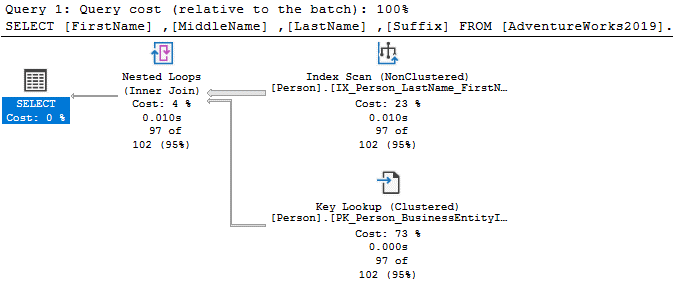
You can avoid the unexpected result using the wildcard character at the end of the string.
SELECT Top 10 [FirstName] ,[MiddleName] ,[LastName] ,[Suffix] FROM [AdventureWorks2019].[Person].[Person] Where firstname like 'Ken%'
Now, you get the filtered result based on your requirements.
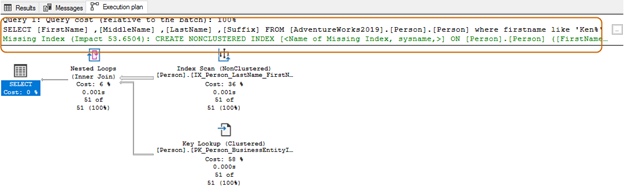
In using the wildcard character at the beginning, the query optimizer might not be able to use the suitable index. As shown in the below screenshot, with a trailing wild character, query optimizer suggests a missing index as well.
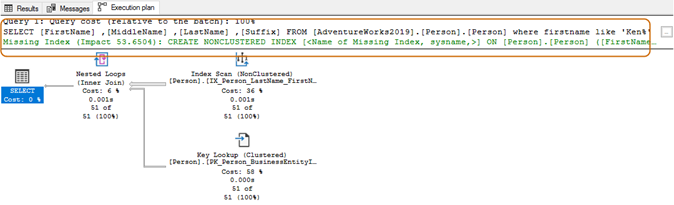
Here, you’ll want to evaluate your application requirements. You should try to avoid using a wildcard character in the search strings, as it might force query optimizer to use a table scan. If the table is enormous, it would require higher system resources for IO, CPU and memory, and can cause performance issues for your SQL query.
Use of the WHERE and HAVING clauses
The WHERE and HAVING clauses are used as data row filters. The WHERE clause filters the data before applying the grouping logic, while the HAVING clause filters rows after the aggregate calculations.
For example, in the below query, we use a data filter in the HAVING clause without a WHERE clause.
Select SalesOrderID, SUM(UnitPrice* OrderQty) as OrderTotal From Sales.salesOrderDetail GROUP BY SalesOrderID HAVING SalesOrderID>30000 and SalesOrderID<55555 and SUM(UnitPrice* OrderQty)>1 Go
The following query filters the data first in the WHERE clause and then uses the HAVING clause for the aggregate data filter.
Select SalesOrderID, SUM(UnitPrice* OrderQty) as OrderTotal From Sales.salesOrderDetail where SalesOrderID>30000 and SalesOrderID<55555 GROUP BY SalesOrderID HAVING SUM(UnitPrice* OrderQty)>1000 Go
I recommend using the WHERE clause for data filtering and the HAVING clause for your aggregate data filter as a best practice.
Usage of the IN and EXISTS clauses
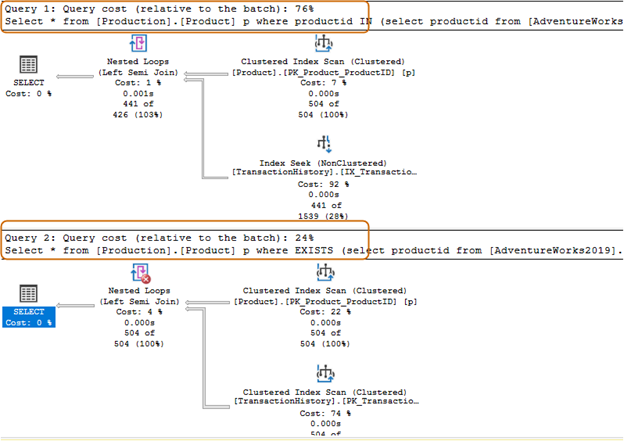
You should avoid using the IN-operator clause for your SQL queries. For example, in the below query, first, we found the product id from the [Production].[TransactionHistory]) table and then looked for the corresponding records in the [Production].[Product] table.
Select * from [Production].[Product] p where productid IN (select productid from [AdventureWorks2019].[Production].[TransactionHistory]); Go
In the below query, we replaced the IN clause with an EXISTS clause.
Select * from [Production].[Product] p where EXISTS (select productid from [AdventureWorks2019].[Production].[TransactionHistory])
Now, let’s compare the statistics after executing both queries.
The IN clause uses 504 scans, while the EXISTS clause uses 1 scan for the [Production].[TransactionHistory]) table].
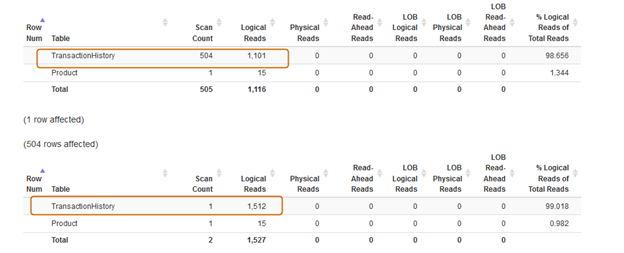
The IN clause query batch costs 74%, whereas the EXISTS clause cost is 24%. Therefore, you should avoid the IN clause especially if the subquery returns a large dataset.
Missing indexes
Sometimes, when we execute a SQL query and look for the actual execution plan in SSMS, you get a suggestion about an index that might improve your SQL query.
Alternatively, you can use the dynamic management views to check the details of missing indexes in your environment.
- sys.dm_db_missing_index_details
- sys.dm_db_missing_index_group_stats
- sys.dm_db_missing_index_groups
- sys.dm_db_missing_index_columns
Usually, DBAs follow the advice from SSMS and create the indexes. It might improve query performance for the moment. However, you should not create the index directly based on those recommendations. It might affect other query performances and slow down your INSERT and UPDATE statements.
- First, review the existing indexes for your SQL table.
- Note, over-indexing and under-indexing are both bad for query performance.
- Apply the missing index recommendations with the highest impact after reviewing your existing indexes and implement it on your lower environment. If your workload works well after implementing the new missing index, it’s worth adding it.
I suggest you refer to this article for detailed indexing best practices: 11 SQL Server Index Best Practices for Improved Performance Tuning.
Query hints
Developers specify the query hints explicitly in their t-SQL statements. These query hints override query optimizer behavior and force it to prepare an execution plan based on your query hint. Frequently used query hints are NOLOCK, Optimize For and Recompile Merge/Hash/Loop. They are short-term fixes for your queries. However, you should work on analyzing your query, indexes, statistics and execution plan for a permanent solution.
As per best practices, you should minimize the usage of any query hint. You want to use the query hints in the SQL query after first understanding the implications of it, and do not use it unnecessarily.
SQL query optimization reminders
As we discussed, SQL query optimization is an open-ended road. You can apply best practices and small fixes that can greatly improve performance. Consider the following tips for better query development:
- Always look at system resources (disks, CPU, memory) allocations
- Review your startup trace flags, indexes and database maintenance tasks
- Analyze your workload using extended events, profiler or third-party database monitoring tools
- Always implement any solution (even if you are 100% confident) on the test environment first and analyze its impact; once you are satisfied, plan for production implementations