

In a previous article, we explored SQL Server index requirements and performance considerations. When it comes to database performance, performance tuning is without question, one of the most important and complex functions. It consists of many different areas such as SQL query optimization, index tuning and system resource tuning, all of which need to be performed correctly in order to successfully retrieve data quickly.
There are several important areas to consider when it comes to SQL Server indexes, as they can have a significant impact on both your performance tuning efforts and overall database performance. Below are some details on each and the critical roles they play.
SQL Server index best practices
1. Understand how database design impacts SQL Server indexes
Indexing requirements vary between online transaction processing (OLTP) and online analytical processing (OLAP) databases.
In an OLTP database, users perform frequent read-write operations, inserting new data and modifying existing data. They use data manipulation language queries (Insert, Update, Delete) along with Select statements for data retrieval and modifications. For OLTP databases, it’s best to create indexes on the Selected column of a table. Multiple indexes might have a negative performance impact and put stress on system resources. Instead, it is recommended to create the minimum number of indexes that can fulfil your indexing requirements. In OLAP databases on the other hand, you use mostly Select statements to retrieve data for further analytical purposes. In this case, you can add more indexes with multiple key columns per index. You can also leverage columnstore indexes for faster data retrieval in data warehouse queries
2. Create indexes for your workload requirements
When creating a new table in your database, don’t just add indexes blindly. Sometimes, developers put one clustered index and a few non-clustered indexes on it without looking for the queries that use those indexes. There might be an index that does not satisfy the query optimizer requirement; therefore, you should properly analyze your workload and SQL queries (stored procedures, functions, views and ad-hoc queries). You can capture the workload using SQL profiler, extended events and dynamic management views, and then create indexes to optimize resource-intensive queries.
3. Create indexes for the most heavily and frequently used queries
It’s important to group workloads for the most heavily used queries in your system. By creating the best indexes for these queries, it will put the least amount of strain on your system.
4. Apply SQL Server index key column best practices
Since you can have multiple columns in a table, here are a few considerations for index key columns.
- Columns with text, image, ntext, varchar(max), nvarchar(max) and varbinary(max) cannot be used in the index key columns.
- It is recommended to use an integer data type in the index key column. It has a low space requirement and works efficiently. Because of this, you’ll want to create the primary key column, usually on an integer data type.
- You can only use XML data type in an XML index.
- You should consider creating a primary key for the column with unique values. If a table does not have any unique value columns, you might define an identity column for an integer data type. A primary key also creates a clustered index for the row distribution.
- You can consider a column with the Unique and Not NULL values as a useful index key candidate.
- You should build an index based on the predicates in the Where clause. For example, you can consider columns used in the Where clause, SQL joins, like, order by, group by predicates, and so on.
- You should join tables in a way that reduces the number of rows for the rest of the query. This will help query optimizer prepare the execution plan with minimum system resources.
- If you use multiple columns for an index key, it is also essential to consider their position in the index key.
- You should also consider using included columns in your indexes.
5. Analyze the data distribution of your SQL Server index columns
You should examine the data distribution in the SQL Server index key columns. A column with non-unique values might cause a delay in retrieving the data and result in a long-running transaction. You can analyze data distribution using the histogram in statistics.
6. Use data sort order
You should also consider the data sorting requirements in your queries and indexes. By default, SQL Server sorts data in ascending order in an index. Suppose you create an index in ascending order, but your queries use the Order By clause to sort data in descending order.
For example, look at the actual execution plan of the following query.
SELECT [SalesOrderID],
[UnitPrice]
FROM [AdventureWorks].[Sales].[SalesOrderDetail]
ORDER BY UnitPrice DESC,
SalesOrderID ASC;
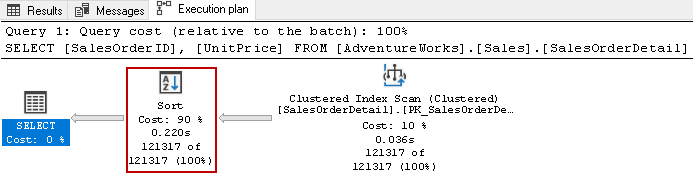
It uses the costly sort operator with an overall 90% cost in this query. We decided to build a non-clustered index on [UnitPrice] and [SalesOrderID]. It uses a default sort order for both columns in the index.
CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_Unitprice
ON [AdventureWorks].[Sales].[SalesOrderDetail]
(UnitPrice ASC, SalesOrderID ASC);
We re-ran the Select statement and the query optimizer still uses the sort operator. It can use the non-clustered index but sorts the data to prepare the result.
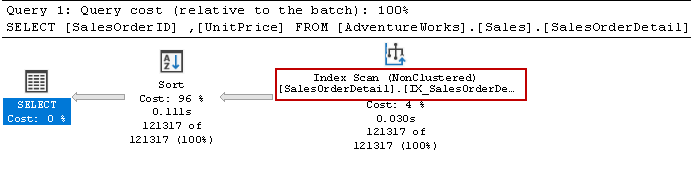
Let’s recreate the index using the following query. This time it sorts data in descending order for [Unitprice] in the index definition.
DROP INDEX IX_SalesOrderDetail_Unitprice ON [AdventureWorks].[Sales].[SalesOrderDetail];
Go CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_Unitprice ON [AdventureWorks].[Sales].[SalesOrderDetail](UnitPrice DESC, SalesOrderID ASC);
Go
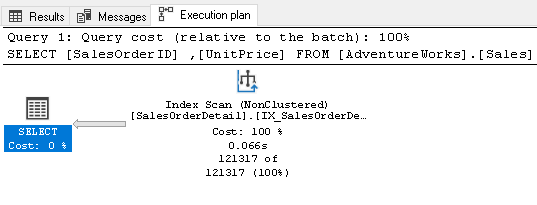
It does not require any sort operator now because the index satisfies the query requirements.
7. Use foreign keys for your SQL Server index
You should create an index on the foreign keys columns. It is advisable to create a clustered index on the foreign key to improve query performance.
8. Be mindful of SQL Server index storage considerations
Index storage is also a useful aspect to consider. SQL Server creates all indexes on the same filegroup of the table. You can consider a separate filegroup for indexes and separate the physical file on a separate disk. This will increase IO performance and throughput.
Similarly, you can use table partitioning to segregate data across multiple disks and filegroups. You can design partitioned indexes for these table partitions to improve concurrent data access.
Another option is to define the FILLFACTOR while creating or rebuilding an index. A FILLFACTOR defines the free space in the leaf node data pages. It is useful for further data insertions. If your data is static and does not frequently change, you can consider a high value of the FILLFACTOR. On the other hand, for frequently changing data, you can leave enough room for new data insertions.
9. Find missing indexes
Sometimes, you get information about a missing SQL Server index in the query execution plan. You can also run the dynamic management views to find these missing indexes. You should not blindly create these indexes. It is merely a query optimizer suggestion, but it does not consider the existing index or your workload requirements. It might also include multiple columns in the index definition, so review these suggestions before implementing it.
10. Always create a clustered index before a non-clustered index
As a general guideline, you should create a clustered index before building non-clustered indexes. If a table does not have an index, a non-clustered index consists of row identifiers. Once you create a clustered index, SQL Server needs to rebuild these non-clustered indexes so that they can point to the clustered index key instead of the row identifiers.
11. Monitor index maintenance and update statistics
Below are several maintenance areas to monitor when it comes to SQL Server indexes.
- Remove index fragmentation: You should regularly review internal and external fragmentations, especially for the high transaction tables. Your queries might respond slowly even if you have proper indexes for your workloads. A heavily fragmented index might degrade the performance because it requires additional IO. You can perform a reorg or rebuild an index based on its fragmentation values. Usually, you should rebuild the index if it has a fragmentation greater than 30% and reorganize it if it has less than 30% fragmentation.
- Remove unused indexes: You should always review the unused (idle) indexes in your database because the query optimizer needs to consider them for each query. An unused index also consumes storage and increases maintenance overhead.
- Update statistics: You should periodically update the statistics even if you have set the auto-update statistics within your database configuration. The query optimizer might prepare a bad execution plan if the index statistics are not updated. You can schedule an agent job to update SQL Server statistics with a full scan after business hours.
You can refer to SQL index maintenance for further insights on this topic.
Applying SQL Server index best practices
Although, there is not always a straightforward way to design an optimal SQL Server index, applying the recommendations specified in this post will help you navigate the varying indexing requirements you will encounter with each database type and its workloads. These best practices will help optimize your indexes to improve database performance and ensure a smoother performance tuning process along the way.


