

SQL Server indexes are used to help retrieve data quicker and reduce bottlenecks impacting critical resources. Indexes on a database table serve as a performance optimization technique. You may wonder – how do indexes increase query performance? Are there such things as good and bad indexes? Suppose you have a table with 50 columns, is it a good idea to create indexes on each of the columns? If we create multiple indexes, does it help SQL queries run faster?
All great questions, but before we dive in, it is essential to know why indexes may be required in the first place.
Imagine you visit a city library that has a collection of thousands of books. You’re looking for a specific book, but how will you find it? If you went through each book, in each rack, it could take days to find it. The same applies to a database when you are looking for a record from the millions of rows stored in a table.
A SQL Server index is shaped in a B-Tree format that consists of a root node at the top and leaf node at the bottom. For our library books example, a user issues a query to search for a book with the ID 391. In this case, the query engine starts traversing from the root node and moves to the leaf node.
Root Node – > Intermediate node – > Leaf node.
The query engine looks for the reference page in the intermediate level. In this example, the first intermediate node consists of book IDs from 1-500 and the second intermediate node consists of 501-1000.
Based on the intermediate node, the query engine traverses through the B-Tree to look for the corresponding intermediate node and the leaf node. This leaf node can consist of actual data or point to the actual data page based on the index type. In the below image, we see how to traverse the index to look for data using SQL Server indexes. In this case, SQL Server does not have to go through each page, read it and look for a specific book ID content.
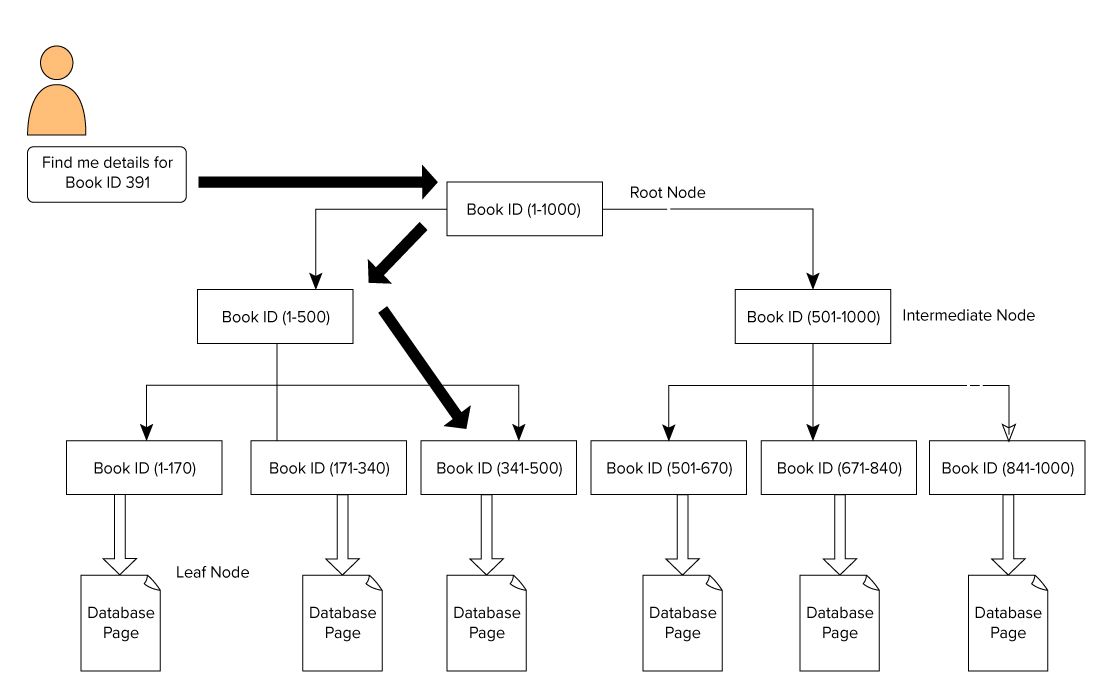
Impacts of indexes on SQL Server performance
In the previous library example, we examined the potential index performance impacts. Let’s look at the query performance with and without an index.
Suppose we require data for the [SalesOrderID] 56958 from the [SalesOrderDetail_Demo] table.
SELECT *
FROM [AdventureWorks].[Sales].[SalesOrderDetail_Demo]
where SalesOrderID=56958
This table does not have any indexes on it. A table without any indexes is called a heap table in SQL Server.
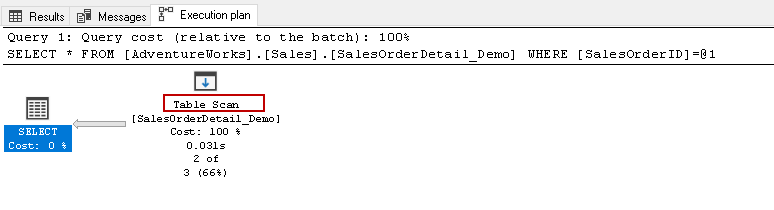
From here, you would want to run the above select statement and view the actual execution plan. This table has 121317 records in it. It performs a table scan, which means it reads all rows in a table to find the specific [SalesOrderID].
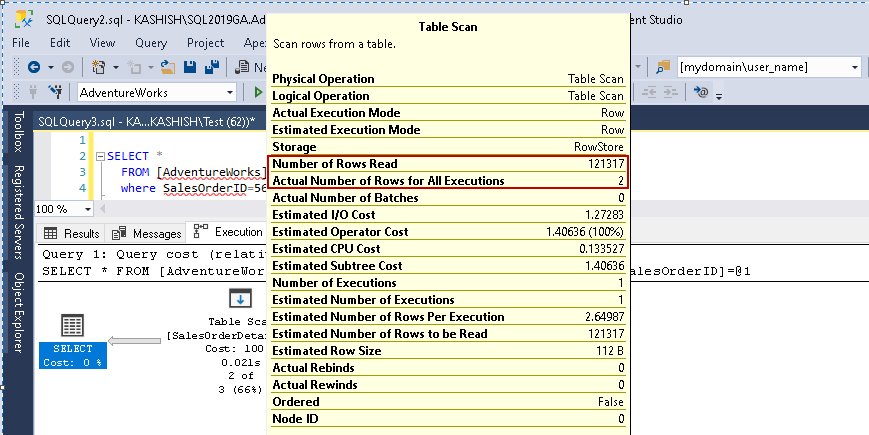
When you hover your cursor over the Table Scan icon, it shows that the actual result set contains 2 rows, but for this purpose, it read all rows in that table.
- Number of rows read: 121317
- The actual number of rows for the execution: 2
Now, think of a table with millions or billions of rows. It is not a good practice to traverse through all the records in the table to filter a few rows. In an extensive online transaction processing (OLTP) database system, it does not use server resources (CPU, IO, memory) effectively, therefore, the user could face performance issues.
Now, let’s run the above select statement with the table having indexes. This table has a primary key clustered index and two non-clustered indexes on [ProductID] and [rowguid] columns. We will talk later about the different types of indexes in SQL Server.
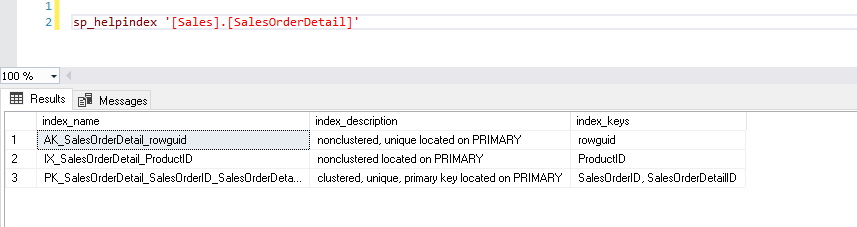
Now, if you rerun the select statement with the same predicate, the execution plan shows the performance issue. Query optimizer decides to use clustered index seek in place of a clustered index scan.
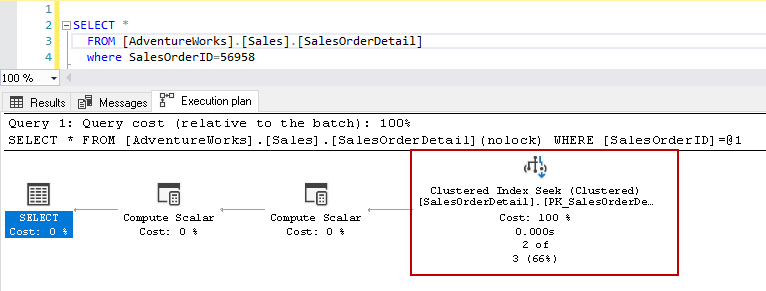
In the clustered index seek details, it shows query optimizer precisely read the rows it gave in the output.
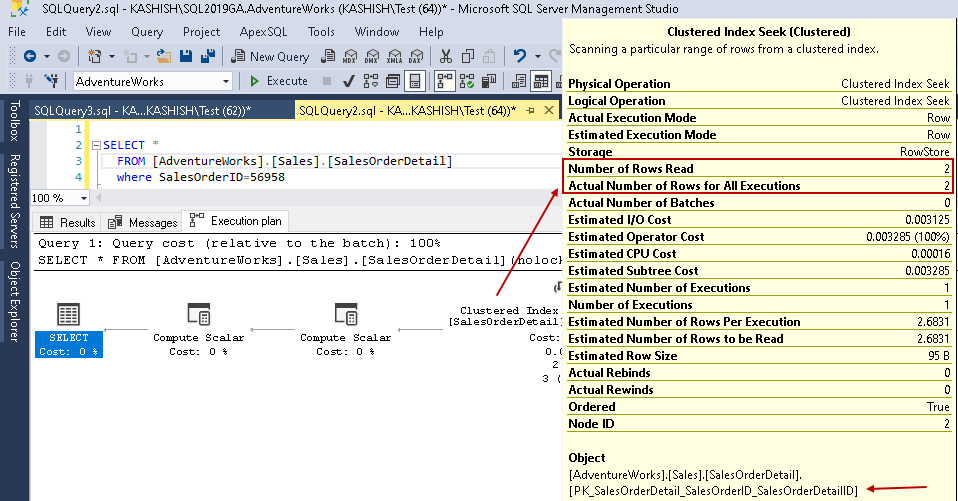
To provide you with a comparative analysis, let’s compare the execution plan with and without a SQL Server index. You can refer to SQL Shack’s How to compare query execution plans in SQL Server 2016 article for further insights.
For this example, look at the highlighted values in the clustered index seek and table scan:
- Logical reads: SQL Server database engine reads a page from the buffer cache and it causes a logical read. Below, we see logical reads are reduced from 1715 to 3 once you create the index.
- Estimated CPU cost also drops from 0.133527 to 0.00016
- Estimated IO cost drops from 1.27283 to 0.003125
The below image shows a difference between a table scan and an index seek.
Good (useful) indexes and bad indexes in SQL Server
As the name suggests, a good index improves query performance and minimizes resource utilization. Can an index reduce the performance of queries in SQL Server? Sometimes we create the index on a specific column, but it is never being used. Suppose you have an index on a column and you perform a lot of inserts and updates for that column. For each update, the corresponding index update is also required. If your workload has more write activity, and you have many indexes on a column, it would slow down the overall performance of your queries. An unused index might also cause slow performance for select statements as well. The query optimizer uses statistics to build an execution plan. It reads all the indexes and their data sampling, and based on that, it builds an optimized query execution plan. You can track your index usage using the dynamic management view sys.dm_db_index_usage_stats and monitor the resources, such as user scan, the user seeks and user lookups.
SQL Server index types and considerations
SQL Server has two main indexes – clustered and non-clustered indexes. A clustered index stores the actual data in the leaf node of the index. It physically sorts the data within the data pages based on the clustered index key. SQL Server allows one clustered index per table. You may join multiple columns to build a clustered index key. A non-clustered index is a logical index, and it has the index key column that points to the clustered index key.
We can have other indexes in SQL Server as well such as XML index, column store index, spatial index, full-text index, hash index, etc.
You should consider the following points before building an index in SQL Server:
- Workload
- The column on which the index is required
- Table size
- Ascending or descending order of column data
- Column order
- Index type
- Fill factor, pad index and TempDB sort order
SQL Server index benefits, implications and recommendations
Indexes in a database can be a double-edged sword. A useful SQL Server index enhances the query and system performance without impacting the other queries. On the other hand, if you create an index without any preparation or consideration, it might cause performance degradations, slow data retrieval and could consume more critical resources such as CPU, IO and memory. Indexes also increase your database maintenance tasks. Keeping these factors in mind, it’s always best to test an appropriate index in a pre-production environment with the production equivalent workload, then analyze performance and decide whether it’s best to implement it on a production database. There are many more recommendations to take into account, check out my top 11 index best practices for further insight.


