

Modern technology has brought about the expectation that services are always on and always available, otherwise noted as “high availability.” However, there are no guarantees that IT infrastructure will remain reliable despite the best efforts of teams and organizations. Software, servers and hard drives will all eventually fail given enough time. Many organizations are aware that they need to invest in developing reliable systems for unreliable environments to be prepared to survive adverse events with as little disruption as possible. Committing to high availability brings enterprises a long way forward to becoming operationally resilient and ensuring the service a business requires is maintained.
The content below concerns high availability architectures and the dependency of databases. It gets somewhat technical with respect to some of the definitions, but it’s worth highlighting that the technology is to support business outcomes and performance of a service. If a business requires a service to run 24 hours a day, 7 days a week, 365 days a year (an e-commerce platform for example), then it is a business requirement to be always-on. High availability architecture is concerned with designing the system to meet that performance requirement, measuring the level of service, monitoring and maintaining the service to ensure business needs are met.
What is high availability and why is it important?
“High availability” or “high availability architecture” is the ability of a system to remain as operational and accessible to users as possible, even during planned and unplanned outages.
Financial loss and data loss become a significant threat to organizations that operate with unstable and unreliable systems. Therefore, stable and reliable IT infrastructure is crucial to the bottom line of many companies. If—for example—the systems that process online orders for a company were to experience significant downtimes, this can result in severe financial consequences due to lost sales.
Data loss can happen due to any number of events: hardware failures, software bugs, human errors or ransomware attacks. Experiencing data loss impedes progress, may involve legal consequences, can be costly to recover, and can result in financial loss.
In each of these instances of potential disaster, developing systems for high availability minimizes the risk of financial and data loss from planned and unplanned outages.
Though achieving a 100 percent availability goal is admirable, it’s not realistic. Modern processes, technology and best practices will help offset the burden of developing and implementing a high availability infrastructure, but business and operations teams must also understand the costs, challenges and required resources that need to come alongside developing a stable implementation.
So what can organizations do to start developing a high availability architecture?
Measuring the success of high availability
One of the measures of high availability is achieving “five 9s.” In essence, the measure of uptime and availability of a system or service. You can see from the table below that achieving five 9s means only five minutes of unplanned downtime in a year for a system or service. That’s an incredible level of service that’s now regularly achieved.
| Uptime percentage | Total downtime per year |
| 90% Uptime | 36 days and 12 hours of downtime / year |
| 99% Uptime | 3 days, 15 hours and 36 minutes of downtime / year |
| 99.9% Uptime | 8 hours and 45 minutes of downtime / year |
| 99.99% Uptime | 52 minutes and 34 seconds of downtime / year |
| 99.999% Uptime | 5 minutes and 15 seconds of downtime / year |
Achieving the five 9s is often the goal for systems and services key to business operations (the mission critical or business critical services). However, this can prove to be a difficult challenge across the various services and applications organizations use in their daily operations.
Even if most services organizations use have a typical 99 percent uptime, the times when one or more services go down can impact a business’s overall availability and performance. The image below demonstrates the impact of individual service level agreements (SLA) on the overall measure of availability. Anyone who has outsourced individual services with SLA terms and are wondering why the total SLA is not meeting the target threshold of availability, this is why. SLAs are contracts that specify the availability percentage customers can expect from a system or service.
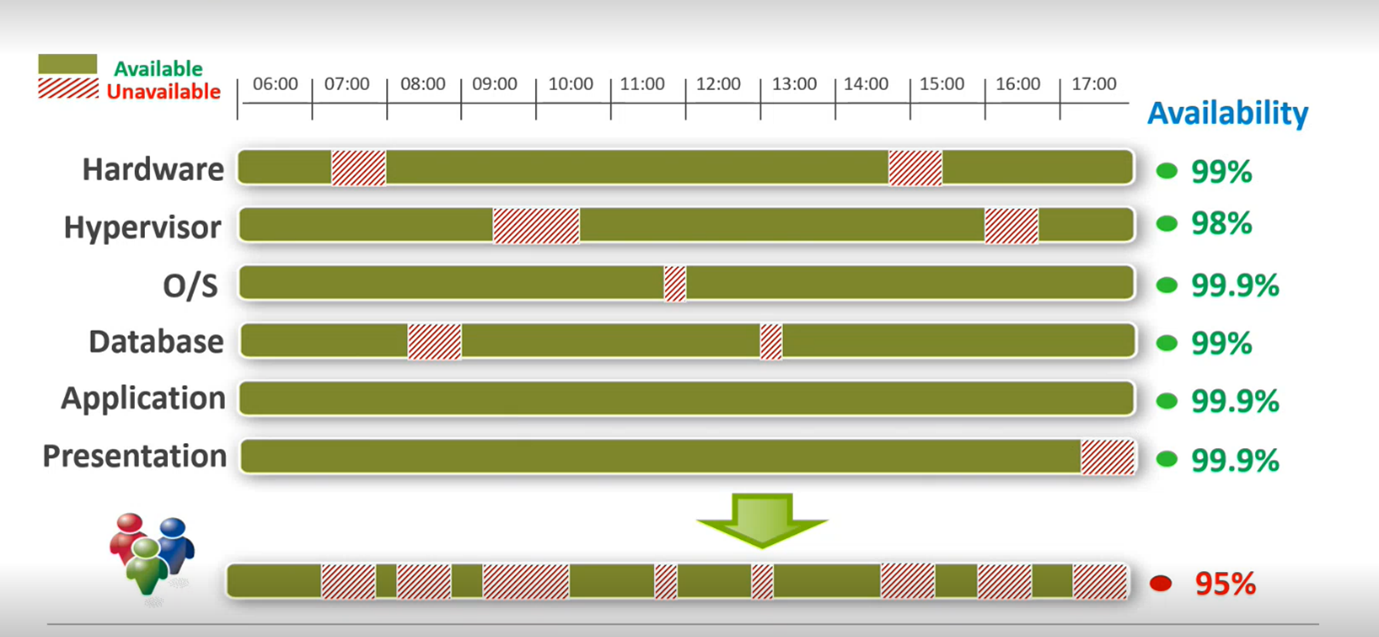
There are three measures of availability that the SLA will reference:
Recovery Time Objective (RTO); is the total time a planned outage or recovery from an unplanned outage will take.
Mean Downtime (MDT); is the average time that a system is non-operational.
Mean Time Between Failures (MTBF); is the expected time between two failures for the given system.
Availability metrics are subject to interpretation as to what constitutes the availability of a service to the end user. Though technically a service may still be available, users may consider the service deficient in performance and unproductive. Despite this, availability metrics should be formalized concretely in SLAs, which the service provider or system is responsible for satisfying.
Careful analysis is needed across the organization to measure and determine the individual service SLA and the impact on the total SLA. Secondly, the SLA is in place to support business requirements. It’s not an arbitrary number or stick to beat the services team with. Analysis should identify how much downtime is actually tolerable.
Techniques to achieve high availability of the database
In order to achieve the five 9s of high availability, teams often have to rely on various techniques and solutions to make it possible.
Failovers
Failovers allow organizations to automatically switch to standby systems to ensure that if a principal system breaks or fails, a backup system can seamlessly stand in and lessen any negative impacts to users. When developing a high availability architecture, failovers are a necessary piece of the overall infrastructure. However, redundancy is key to establish before failovers. Without redundancies in place, organizations have nowhere to failover to.
Data redundancy & distribution
Data redundancy means all data is stored and backed up in perpetuity. Data redundancy aims to give an extra shield of protection and reinforcement to backups by replicating data into an alternate system.
Pairing redundancy and storing data in two different locations on top of extra distance between where that data is stored, gives organizations geo-redundancy.
For example, if data is stored in data centers in two different countries, that geo-redundancy can bolster data protection in case an adverse event happens in one location.
While it’s a good idea to have geo-redundancy, it can also introduce questions organizations need to account for. For example, replicated data in data centers in two different countries may run into latency issues, where it takes data longer to be stored or retrieved based off of its more distant location. Additionally, if data resides within one country with strong data protection laws, and replicated data is stored in a location with weaker data protection laws, questions around data residency and data sovereignty will come into play.
Additionally, data redundancy is fundamentally different compared to instance redundancy. Instance redundancy refers to having replicas of a database running simultaneously. In the case of a database failure, a replica is an up-to-date, running database that can take over immediately. In the case of instance redundancy and not data redundancy, if a database goes down, the redundant database instance that you have access to will not be useful as it is not up-to-date and cannot take over. Both need to be redundant.
While those questions are important for any organization to address, the benefits of data redundancy and distribution often outweigh any of those issues. The key benefits of data replication are:
- Geo-redundancy
- Horizontal scaling
- Reliability
- Performance
- Heterogeneity
- Replication
For those looking to further enhance fault tolerance, a Shared-Nothing architecture might be a path to consider. Shared-Nothing databases have independent servers and don’t share memory, computing power or storage. This allows for higher availability because select data is isolated to independent nodes, interconnected by networks in an aim to remove contention between nodes.
Altogether, this type of infrastructure can be referred to as “distributed systems,” which serves a key need for data availability. Because systems and data are spread out, it allows data to be more accessible to end users, can reduce latency, improve fault tolerance and in return, enhance a customer’s experience.
Clustering
Server clusters can be used to improve server reliability. However an organization decides to implement a server cluster can span computers that share storage, to large groups of servers that have software that evaluates usage and can distribute workloads. If usage expands, an advantage of clustering is that computing power can be increased through the addition of another server (this is effectively a simple form of cloud elasticity and scaling horizontally). Automatic recovery from failure without intervention is another advantage.
The big problem with clustered solutions is how complicated they are to set up and maintain, and if your database is corrupted they can end up beyond-repair. Obviously as pointed out above, Cloud Service providers have provided automated elastic services to meet their customer’s high-performance service requirements.
Despite this, there are two main types of clustering that organizations often implement.
Instance-level clustering
Instance-level clustering allows database instances to be protected by deploying several instances in different hosts. The database itself is hosted on remote storage, but is visible to all necessary hosts.
Depending on organizational preferences, there are typically two types of instance-level clustering.
- Active/Passive clustering
- Active/Passive clustering only allows one instance to process database client requests. If there are issues with the current active instance, a passive instance will come online and become the new active instance. Unfortunately, Active/Passive clustering is frequently used as a failover method and isn’t a great method to achieve five 9s in a high availability architecture.
- Active/Active clustering
- Active/Active clustering processes client requests in parallel. Any issues with one active cluster will automatically route database client requests to the other active remaining instances.
Database-level clustering
Database-level clustering refers to the occurrence of a database-level protocol pushing out changes across additional databases. There are typically two different ways this is accomplished.
- Physical replication:
- Data gets copied on the physical level, at a lower level than database operations. This means that we are not applying the operations but copying the bytes that were affected by the operations. We can ensure that the state of the database is exactly the same, since they are identical, byte for byte. Over long distances there are some limitations and additional costs, especially when it comes to the cloud. This comes from the lack of knowledge about the database structure; it is impossible to grab a snapshot of some collection or objects from a database and ignore others. Say when only a portion of a database has changed, why is it necessary to copy the entire database and not adopt just one small change?
- Logical replication:
- Logical replication supports heterogeneous hardware and software. Customers can pick and choose which tables to be replicated, and can replicate from just a few columns or few rows in a table to the entire table itself. In most cases, logical replication offers greater flexibility.
Data replication
Replication can help ensure high availability essentially by maintaining several database copies across different sites. As long as one site location is up, running and accessible, the data service is available to use. Conversely, if one site goes down, the services can still access necessary data from another site.
While redundancies must be part of an overall high availability architecture, data replication offers much more flexibility than relying solely on redundancies. From data consolidation across various sources into data marts or data warehouses, synchronization across geographic locations, maintain data integrity across multiple databases and resolve data conflict.
High availability architecture within the context of the cloud
These days, developing a high availability architecture and working towards increasing resilience by architecting for redundancies and fault tolerance can’t typically be discussed without talking about cloud native architectures.
Cloud native architectures are often built to help organizations easily scale and adapt to temporary surges in demand. Many organizations prefer to build a cloud native architecture for their additional flexibility and scalability.
Cloud native architectures are often built to use microservices with applications across distributed nodes by design. However, it’s crucial to plan for potential failures that may impact one node. Even if a node with a microservice fails, a well-designed system should have failovers, redundancies and replication in place to help recover services.
Other considerations for high availability architecture
Exploit native features
No matter what database management system an organization employs, there are often features and releases added that further support technologies to enhance high availability for databases. Ideally, the database technologies used are designed with high availability in mind and have been engineered to have native features that help strengthen overall uptime.
Take advantage of automation
There are plenty of tasks and events surrounding resiliency and high availability architectures that can be automated. Regular manual tasks will often introduce manual errors, and automation can safeguard against errors due to human mistakes. If done incorrectly, the complex—but regular—tasks of data backup and recovery, adding new data into a database, checks for data quality and integrity, and the collection of stats regarding database usage can cause severe availability issues. By taking advantage of automation, engineers can focus on further developing resilience and fortifying against adverse events.
Maintenance schedule
To maintain a high availability architecture, regular maintenance is critical. To achieve five 9’s, a regular service schedule paired with a backup strategy has to be put into operating plans. Deferred maintenance can be a disaster, especially during a crisis. Beyond a regular service schedule and backup strategy, regular testing of disaster recovery plans is essential.
In closing
Organizations that are working towards developing high availability architectures are preparing for the “when,” not “if” of a failure in their infrastructure. While IT infrastructure may become unreliable over time with improper maintenance and planning, the teams and organizations that commit to high availability and aim for five-9s are well on their way to becoming disaster ready and operationally resilient.


