Data replication has moved from “nice to have” to “mainstream” for use cases such as High Availability and Disaster Recovery. At the same time, companies are discovering the need to replicate or move data for other reasons, including performance and translating transactional data into events.
What is data replication?
Data replication is the process of updating copies of your data in multiple places. The goal of replication is to keep your data available to the users who rely on it to make decisions and to the customers who need it to perform transactions.
How does data replication work?
Data replication works by keeping the source and target data synchronized. That means that any changes to the source data are reflected in the target data.
Depending on your data replication strategy, your target database can be the same as the source (full-database replication) or the target can be a subset of the source (partial replication). If your goal is high availability or disaster recovery, it makes sense to maintain full replicas. For analysis, reporting, or event tracking you can reduce the workload on the source database by replicating subsets, according to region, business function or event, of the data from source to targets.
The data copies required for replication can be performed in several different ways.
The simplest of these is a snapshot or copy of the data taken at some point in time. This sort of replication is typically used for backups, or in cases where the data on the target can be older than data on the source. The disadvantage of snapshots is that they are just that, a snapshot or picture of your data at a particular point in time. If the source data changes, those changes are not reflected in the target until the next snapshot is taken. Also, snapshots are typically taken of the entire database, which can be time consuming,
Another technique sometimes used for replication is merge replication. Merge replication involves recording changes made to the source and then applying those changes in a batch to the target. Since the data must be processed multiple times there can be performance issues with merge replication.
The predominant form of replication in use today is transactional replication. In this form of replication, changes or transactions being applied to the source are captured and then applied to the target. Transactional replication can apply the changes from the source to the target in near real-time, most of the delay is the time it takes to move the data from the source to the target. This overcomes the lag or latency challenges presented by snapshot or merge replication.
What are the benefits of data replication?
You’ll be surprised at how many advantages there are to having your data in more than one place at a time.
Here’s another: for data integration projects. When you’re pulling together large amounts of data from multiple sources, sending data from all those sources to a replication target keeps production data available. Meanwhile, integration tools aggregate the data from the different silos and make it available for operations and analysis.
Being data-driven means removing as many roadblocks as possible between users and databases. Data replication is a big step toward getting your data in as many places as your users need it.
Examples of data replication
The more your business relies on data, the more important it is to make sure there is no single point of failure. When you replicate your data to targets in other cities or time zones, you help ensure that users and customers can always access it.
- IT administrators often turn to data replication for disaster recovery. With their data safely maintained at two or three different sites, they are less vulnerable to business interruption in case of a system breach or disaster at any single site. And, because the replica is always up to date, business continuity is just a matter of redirecting traffic away from the disabled source to the target site.
- In an era when customer bases and development teams follow the sun, geo-diverse database replicas keep data close to the people who need it. Data replication is a useful strategy for overcoming network latency and improving performance for local access.
- Real-time analytics are integral to competitive advantage, so line-of-business managers want to run queries and base their decisions on current transactions. To keep those queries from burdening the source, administrators create and maintain replicas for use by analysts and offload that work from the production database.
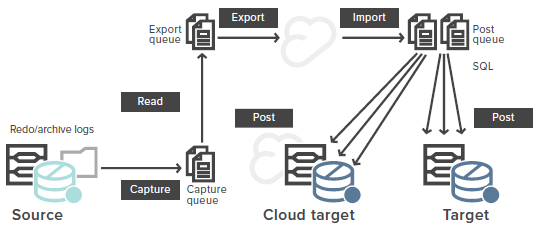
The image below depicts a log-based replication architecture, with data flowing from source to target and cloud.
Synchronous vs. asynchronous replication
Data replication can be synchronous, where data from multiple locations is kept synchronized at all times and a change is not considered complete until it is completed on both source and target; or asynchronous, where changes to the source and target are independent and changes to the target may be delayed.
Typically, synchronous replication takes more resources and can result in performance bottlenecks. Synchronous replication sets up a “two-phase commit” situation, where until the data is available in all locations, it’s not available at all. This can cause performance issues with online transaction processing or other time-sensitive systems. It can also be an issue with systems located far from each other, since data can’t yet move faster than the speed of light.
Synchronous replication is normally used only when the consequences of unsynchronized or lost data are higher than the associated costs. Normally, once data is written once, it’s considered secure, and a short lag between the source and target is acceptable. With today’s optimized software and hardware, the asynchronous replication is generally tolerable.
Why is data replication important?
Data replication technology lets your organization use your databases in two, five or a dozen places at the same time.
So, why is replication so important? I’ll explain how you can replicate data to your advantage in three important areas:
- Analysis and reporting
- Upgrades and migrations
- High availability and disaster recovery
- Translate transactions into events
Analysis and reporting
“Replication isn’t such a big deal,” you say. “I can email a data file to 20 people. Then I’d have my data in 20 places at the same time.”
That’s true. But what if it was ever-changing sales data from your e-commerce site, or real-time data based on your company’s social media? By the time recipients had opened your data file and started analysis, they would be studying old news. It would be like reading a printed newspaper: The longer they studied the data in the file, the less current its story would be. You’d have to send out an updated file every time there was a new or changed transaction.
Besides, sending a data file doesn’t scale up very well. It may work for a 100KB or 700KB spreadsheet full of data, but what about a 500GB database? You couldn’t send that out every hour.
“In that case,” you say, “I’d let everybody log onto and query the production database. Then, we would all query and analyze exactly the same data at the same time.”
Yes, that way nobody would be studying old news.
But then you’d have a congestion problem in your database. The reports you ran would compete for memory and CPU cycles against the reports that all the other analysts were running. And all those reports would compete against the transactions of customers who pay your salary and keep the lights on.
Data replication is a more efficient, more elegant solution for putting nearly real-time data in front of the analysts who can take action on it.
Upgrades and migrations
The argument for replication is different in the data center, where IT administrators are trying to perform a migration or an upgrade. There, the pressure comes not from the need to run reports but from the need for business continuity. Customers and users don’t care that there’s a migration or upgrade going on; they want full access to the data without interruption.
“No problem,” you say. “When we migrate/upgrade, we can back up our databases and restore them to the target. Once we have all our data in two places, we’ll start the migration/upgrade. Then, as soon as it’s finished, we’ll point all our users to the new environment.”
But what about all the transactions that have been changed and added in the meantime? It will take you a while to bring the new environment into sync with the old one. And what will you do if there are problems in the new environment? You’ll have to roll things back to where they were before, then try again. That’s not business continuity — that’s business on-again-off-again.
Data replication lets you maintain an accurate, real-time copy of production data to upgrade and migrate databases without risk. It keeps source and target in sync until testing is complete when you can confidently switch users over to the new, upgraded environment.
High availability and disaster recovery
Database administrators are responsible for ensuring databases run smoothly while keeping an eye on high availability, disaster recovery and the five nines of uptime. Unscheduled downtime results in the loss of service, data, money and customers, so the job is all about keeping multiple databases and platforms running efficiently. High availability ensures the data is always there for users, and disaster recovery is the big backstop in case the data suddenly isn’t there.
“Our database includes native tools for high availability,” you say, “And we use another tool to keep remote copies running for disaster recovery. That’s how we have our data in more than one place.”
Native tools are often expensive for the limited functionality they provide and some still have a single point of failure—a shared database. If something happens to that database, your systems will be down while you recover. Besides, a copy is not a replica. A copy is a snapshot, and a snapshot of a database is obsolete as soon as a new transaction hits.
A replica, on the other hand, gives you true high availability. Replication means you have databases that can immediately take over for one other in case of failure.
With data replication, you achieve high availability and strengthen disaster recovery. Replication lets you switch users to a secondary system during maintenance or downtime to keep your production data available. Your applications don’t have to wait for you to spin up a copy of an entire disaster recovery database, which means that you won’t lose transactions. Plus, the right high availability product lets you use the same target database for disaster recovery.
Translate transactions into events
In today’s fast-moving business environment, more companies are turning to streaming services, such as Kafka or Azure Event Hub, to track events that are happening in real-time, on either the shop floor or the sales floor. Replication can turn the sales or machine record inserted into your database into an event that can be acted on in real-time, to allow the customer to add a tip or a machine to be serviced.


