Everyone who analyzes data or tries to derive value from it, is affected by data preparation sooner or later.
Why?
Because organizations that identify, analyze and act on their data get the most out of it. That’s where quality of data becomes more important than quantity of data, and preparing the data is how you achieve that quality.
Data preparation requires considerable time and effort, but it’s hard to get value from your data without it. Some database professionals and data scientists regard data preparation as wasted time and effort, keeping them from deriving useful insights. But the real value that comes from data insights can only be achieved by understanding the data through effective data preparation, especially when data comes from multiple, disparate data sources.
The role of data modeling
A good first step in preparing data and extracting value from it is to understand what it includes, which you can do through data modeling.
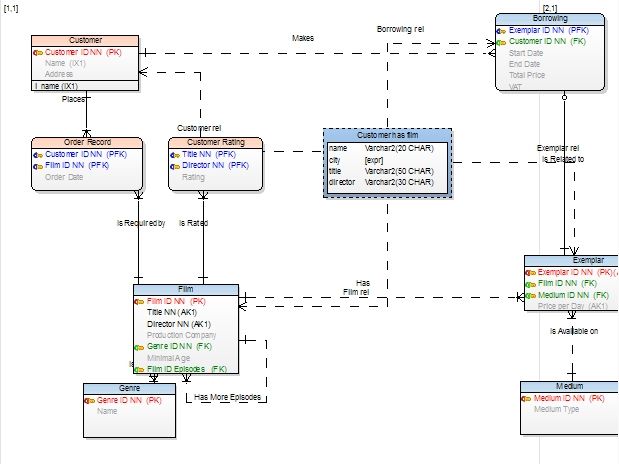
As shown below, the data model is used to design the optimum data structure (tables, relationships, indexes, etc.).The model helps you understand how the database is organized, what it’s designed to do and the types of data defined. Once you understand the framework of the data you’re examining, you can better understand the data itself.
Roadblocks to data preparation
Preparing data fits well among your organization’s database management functions, where databases are built and maintained, and where data sources are merged into warehouses and lakes.
However, things get in the way. Not only does data tend to go stale quickly, but database professionals also face other roadblocks to data preparation:
- Many analysts find themselves with more data sources than they can easily manage. The diversity of data sources per se is not a roadblock, but the process of deciding which ones to use (Oracle, SAP, MySQL, Cassandra, etc.) may be.
- The variety of data sources requires a variety of tools to pull the data. Analysts may use everything from custom, vendor-supplied tools to ordinary SQL queries.
- The variety of sources also brings about data silos, as different departments grow their databases on different platforms. The silos frustrate efforts to corral and analyze the organization’s data in its entirety.
- In some industries, regulations on data governance and compliance impose limits on what analysts can access. The regulations prevent illicit use of the data, but they also hamper the free-range access needed to quickly capitalize on business opportunities.
In short, when trying to understand where all your data resides, the variety of data sources is a mixed blessing. Your data preparation process has to deal with its downside before enjoying the benefits of its upside.
Clean, complete and analysis-ready
One aspect of breaking down silos is resolving technical differences among sources. Without that kind of resolution, any analysis you conduct will still be tentative because the data won’t be consistent across silos.
To achieve the high quality needed in data preparation, focus on three attributes:
- Clean — Is the data ready for analysis, or does it need extensive preparation first? Have you resolved the way your data sources handle issues like date formats, null values, duplicate records and empty fields?
- Complete — Is there enough data for statistical significance and meaningful conclusions? For example, if you want to determine how marketing spend influences customer spend, yet you’re not tracking how your campaigns drive people to your website, then the data is incomplete. It doesn’t matter how much you analyze it, the best you’ll be able to do is to draw inferences, not see actual cause and effect.
- Analysis-ready — Do you need to compute values to make your data more useful? For example, do you have to regroup months into quarters or highlight frequently occurring values? Most real-world data is not analysis-ready right off the bat, so a fair question is, “How much work will it take to get your data ready for analysis?”
Don’t forget dark data
What is dark data? What role does it play in data preparation?
Gartner defines dark data as the information assets your organization collects, processes and stores in the normal course of doing business, but which you don’t use and don’t delete. You hold onto it, but it doesn’t do you any good — quite the opposite, in fact.
First, you’re storing, securing and managing all that data. That means spending more money on it than you’ll ever get out of it. Worse, dark data may contain information you’ve forgotten about or didn’t know was there to begin with. Suppose your company’s dark data contains personally identifiable information (PII) about customers or patients. If they told you to delete any PII you had on them, and you didn’t even know it was there, you could be liable for non-compliance with privacy regulations.
Consumers worry about having their personal information tracked and stored, and dark data is the corresponding worry for businesses. So, how do you avoid collecting data you don’t want, will never use and could someday be penalized for? There is no magic solution, but the data preparation phase is a good time to determine which data needs to be tracked and to stop tracking the rest.
Data preparation tactics/checklist
It’s nice to think that data is immediately useful once it’s in a document store, the fields of a database or the neat rows and columns of a spreadsheet. But there’s always more to it than that. Experienced analysts and database professionals who query a database for the first time want to know what’s in it.
- Where did the data come from? Has it been satisfactorily used before?
- How will outlier records (extremely high or low) be handled?
- Has the data been scanned for duplicates and near-duplicates?
- Are all times and dates in the same format?
- If timeliness matters, can older records be queried out?
- Are there non-Roman characters in the data? How are they encoded?
- Does any of the data need to be translated into a primary language?
It’s hard to be a data-driven organization when you’re spending so much time massaging and wrangling data instead of using it to make decisions. Like packing your own parachute, spending some time preparing data reduces the likelihood of unwelcome surprises when the time comes to use it.
It’s not necessary to spend big money on specialized tools for data preparation. You can use query and data preparation tools to clean your data, make sense of it and prepare it for downstream use in visualization tools, dashboards and data science.
And, as I’ll describe in a future post, they help bring self-service data preparation into your organization. When line-of-business managers and analysts can mine data sources on their own, data scientists are freed up for higher-value predictive analytics.