

Data operations enables your organization to maximize the business value of your data and its underlying infrastructure. It’s the overall approach to designing, building, moving and using your data, both on-premises and in the cloud. It’s the key to digital transformation initiatives such as cloud migration, DevOps, open-source database adoption and data governance.
Does it feel as though your database technology gets in the way of using your data to solve business problems? Maybe you’re aware of how much data your organization is accumulating, but you’re having trouble getting good value from your data assets and infrastructure.
Then it’s time to start thinking about data operations.
What kind of business problems can data operations solve?
The more data you accumulate — and the more you rely on it — the more problems arise.
- Poorly-planned cloud migrations – Have you moved workloads to the cloud in a hurry, without the chance to analyze and monitor them first? When performance problems arose, how did you know where to start looking? Maybe the cloud environment introduced them, maybe not. Data operations ensures that the root cause is not so easily misdiagnosed or hidden.
- Increased agility of database changes – Organizations are trying to apply DevOps practices like continuous integration and continuous deployment to react more quickly to changes in the business. But DBAs tend to not like quick changes to data structures as it can create risks to data, so bottlenecks crop up when IT slows the pace of change in their effort to mitigate risk.
- The balance between “always on” and costs – You can have it all — high availability of mission-critical applications, cloud environment, Oracle databases and offsite data replication — but it costs money. Data operations helps you strike a balance.
- Skills gaps – New databases and infrastructure options tend to de-centralize your IT landscape, yet for support and troubleshooting, everybody always comes back to IT. Can your team keep up with the constant innovation? Research from ESG shows that 36 percent of organizations have glaring gaps in cloud architecture/planning, 34 percent in IT architecture/planning and 32 percent in IT orchestration and automation.
- Disruption of the data pipeline – When your business depends on data and analytics, all eyes are on the data pipeline. The responsibility for keeping data flowing places new urgency on internal systems and data ingestion points.
- Self-service data consumption – If you’re trying to empower line-of-business (LOB) users, too much data can be as big a problem as too little data. Data operations addresses the problem of locating the right data from so many sources and understanding how to connect, access and interpret it.
- Reactive mindset – Being constantly reactive means that database or infrastructure performance problems can overtake you and affect user experience in business-critical applications. You’re better off anticipating those problems than reacting to them.
- Transformation of operations teams –Autonomous databases, artificial intelligence (AI) and machine learning (ML) are changing the traditional role of DBAs, who are looking for new ways to add value to the business. Data operations enables DBAs to embrace change and grow from being experts in the database to being experts in the data.
Data operations is different from DataOps
DataOps provides greater collaboration and delivery of data and insights at real-time speeds to decision makers or decision-making applications. The essence of DataOps is the automation of processes, similar to those used in DevOps, that help democratize data. DataOps doesn’t refer to supporting infrastructure.
Data operations, on the other hand, takes a broader view. It includes the data and the data pipeline: the hybrid infrastructure where data resides and the operational needs of data availability, integrity and performance. Both the data and the pipeline have business value and the goal of data operations is to maximize that value. Within the pipeline is the infrastructure that needs testing, performance monitoring, cost analysis, tuning, securing and so forth.
Four basic steps for implementation
1. Assemble the data.
To put the right data in front of decision makers, IT first designs the data in a way that maintains the organization’s data management framework. So, the first goal of data operations is to capture business requirements that can be translated into an accurate, usable, logical data model.
As obvious as that may sound, consider the downside of not capturing those requirements. If you skip the logical modeling and dive into creating physical data structures and relationships, it’s far more work to incorporate business rules later. Get it right the first time by creating a full, logical model because the friction you’ll face is not worth the little bit of time you’ll have saved.
Data modeling tools introduce two elements at this point: rigor and documentation. Rigor is important because there is more than one way to model data for say, a customer entity. But in your organization, there is only one right way to model it, and rigor ensures that you find that right way and build the model accordingly. As in constructing a building, form (the physical design) follows function (the logical data model).
Documentation is important because of the need to support discovery and documentation of data from anywhere. The goals are consistency, clarity and artifact reuse across initiatives like data integration, master data management, metadata management, big data, business intelligence and analytics. Once you’ve documented the elements of the data model and its physical translation, you have a way to find, visualize, define, deploy and standardize enterprise data assets. Whoever (usually DBAs) creates the data structures to match the logical model’s requirements needs a guide to make that translation. Documentation helps them generate the data definition language (DDL) scripts for those structures accurately, adjust if needed and assemble the data engine.
Next, come the database tools that drive productivity, improve manageability and increase quality in a heterogeneous database environment. The more efficiently developers can create high-quality code that’s free from defects and DBAs can handle or automate routine tasks, the more they can focus on innovation.
2. Move the data to where it needs to be.
There’s a simple truth that drives much of cloud spending: The greater the resource load on the platform, the higher the cost once it’s in the cloud. In this step, data operations includes performance monitoring to ensure there is no problem when a workload goes to the cloud. That means right-sizing your cloud computing resources — CPU, storage, memory, network — to handle the load without breaking your budget.
Here is a simple breakdown of right-sizing tasks:
- Estimate on-premises cost of the entire workload.
- Before migrating, perform a cost study of what looks like the best-fit cloud service tier.
- Optimize the workloads.
- Do a pre-migration load test on the database.
- Document everything.
Your goal is to study workloads for expected cloud resource usage and costs, based on performance on-premises. If you shrink your virtual machines and trim database resource requirements early, you’ll have slimmed-down baselines on hand to compare to workload performance in the cloud after migration.
3. Manage the data across the enterprise.
In a completely on-premises environment, you monitor and optimize databases to maintain performance levels; in the cloud, you monitor and optimize to control cost, also.
Right after cloud migration, the most pressing question centers on performance: How does application performance in the cloud compare to what it was on-premises? According to the 2020 PASS Database Management Survey report, in the cloud, 24 percent of DBAs worry about performance, compared to 41 percent for on-premises databases. The trend points to less time spent on performance management, but the need to monitor performance still grows as more databases go to the cloud.
Within a month or so, concerns switch to cost:
- Are cloud costs acting as expected?
- If costs are higher than estimated, does anyone in the organization understand why?
- How do you know what to adjust?
- Have you selected the right service tier for your workloads?
The goal of data operations in this step is to provide meaningful information to management and the CIO for tuning the current cloud migration strategy. The most useful tools are the ones that show where the organization is overpaying for and under-benefitting from cloud computing. Typical culprits include migrated virtual machines whose costs are increasing because their workloads don’t fit the service tier.
4. Make the data useful.
We’ve seen how the first three steps help in the democratization of data.
To get their hands on the right data, decision makers need applications. Customer-dependent applications are changing all the time because business needs call for it. The goal of data operations is to keep pace with the changes and keep the right data flowing through the organization.
Database DevOps has evolved as a way of keeping quick-turnaround builds reliably safe for production. Like application developers, database developers unit test database code to reduce defects, perform code reviews to reduce technical debt and automatically create change scripts to accurately deploy their changes to the production system.
Finally, companies can fulfill the primary goal of making their data work for them by extracting the important insights necessary to help inform the decisions that drive strategy and enable the business to grow.
What’s needed is a simple, effective way for business users to access all the various data sources they have access to and to create queries and reports without requiring any technical expertise. That way, business users don’t have to wait on data analysts to provide data sets and reports and the path to data insights can become shorter.
Conclusion
Data operations seeks to streamline the delivery of data through increased data democratization into downstream processes like analytics and AI/ML. At the business level, that means extracting insights at scale and maximizing the full value of both data and infrastructure.
The drivers for change that are implemented and managed by IT need to come from the business so that they align with business strategy and drive growth. Companies can attain those goals through data empowerment: a strategy that combines the three pillars of data operations, data protection and data governance.
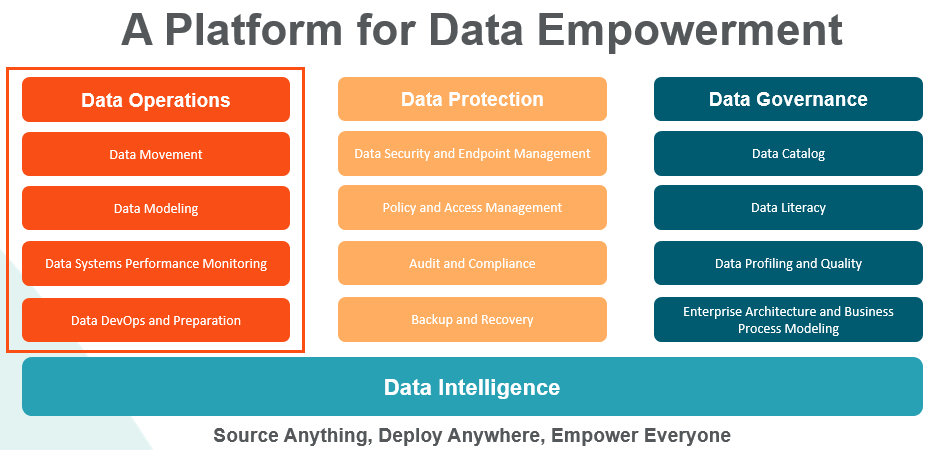
By combining those pillars, businesses are better aligned with fewer data silos, and teams in the front and back office are empowered to work together more efficiently.


