

In this article, we will cover the different methods for using the UPDATE from SELECT statement in SQL Server.
In the database world, static data is not typically stored. Instead, it keeps changing when we update existing data, archive or delete irrelevant data and more. For example, let’s say you have a table that stores product pricing data for your shopping portal. The product prices constantly change, as you might offer product discounts at different times to your customers. In this case, you cannot add new rows in the table because the product record already exists, but you are required to update the current prices for existing products.
This is where the UPDATE query comes into play. The UPDATE query modifies data in an existing row in the database. You can update all table rows or limit the affected rows for the update using the WHERE clause. Usually, SQL updates are performed for an existing table with direct reference. For example, in a [employee] table, a requirement has to increment all active employees’ salary by 10%. In this case, the direct reference SQL query will be:
Update employee set [salary]= salary + (salary * 10 / 100) where [active]=1
Suppose you have another table [Address] that stores employees’ locations and you are required to update the [Employee] table based on the data available in the [Address] table. How do you update data in the [Employee] table?
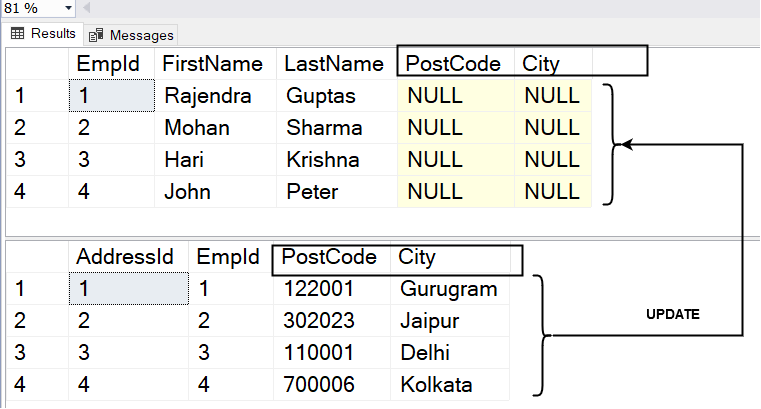
Luckily, there is a solution – UPDATE from SELECT statement. In the following section, we look at different ways for performing updates using a SELECT statement. For example, the [Employee] table has NULL values for columns – [PostCode] and [City] in the following screenshot. The [Address] table has values for both columns [PostCode] and [City].
Method 1: UPDATE from SELECT statement: Join Method
This method uses SQL Joins for referencing the secondary table that contains values that need to be updated. Therefore, the target table gets updated with the reference columns data for the specified conditions.
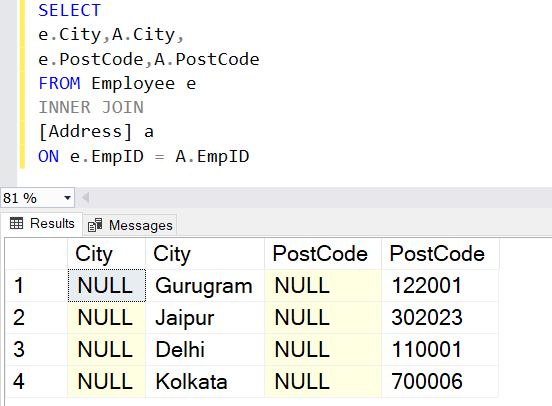
It is pretty straightforward to use the UPDATE from SELECT statement in this instance. You can first use the SELECT statement to fetch the reference column and target column values.
SELECT e.City,A.City, e.PostCode,A.PostCode FROM Employee e INNER JOIN [Address] a ON e.EmpID = A.EmpID
Next, you will perform slight changes in your query, and it will prepare an UPDATE statement as shown below.
- Replace the select keyword with update.
- Specify the table name or alias name that needs to be updated.
- Use a set keyword and equals symbol (=) between referencing and target columns.
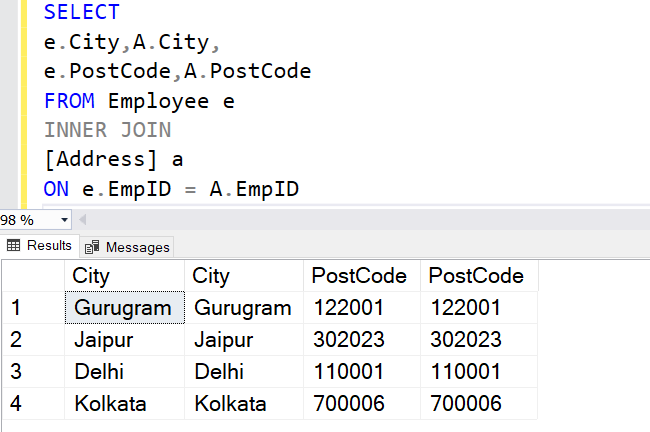
UPDATE e set e.City=A.City, e.PostCode=A.PostCode FROM Employee e INNER JOIN [Address] a ON e.EmpID = A.EmpID
Then execute the UPDATE statement and verify that the source and target column values are the same.
Method 2: UPDATE from SELECT: The MERGE statement
The MERGE statement is useful for manipulating data in the target table based on the source table data for both matched and unmatched rows. It is an alternative method for performing the UPDATE from the SELECT statement function.
In the example MERGE statement below, the following tasks are performed:
- Use a MERGE statement for updating data in the [Employee] table.
- It then references another table when the USING clause is applied.
- The WHEN MATCHED then specifies the merge JOIN (Inner Join) between the source and target table.
- It then updates the [PostCode] and [City] from the [Address] table into the [Employee] table using the THEN UPDATE statement followed by source and target column mappings.
- The MERGE statement always ends with a semicolon(;).
MERGE Employee AS e USING(SELECT * FROM [Address]) AS A ON A.EmpID=e.EmpID WHEN MATCHED THEN UPDATE SET e.PostCode=A.PostCode , e.City = A.City;
Method 3: UPDATE from SELECT: Subquery method
The subquery defines an internal query that can be used inside a SELECT, INSERT, UPDATE and DELETE statement. It is a straightforward method to update the existing table data from other tables.
UPDATE Employee SET Employee.City=(SELECT [Address].city FROM [Address] WHERE [Address].EmpID = Employee.EmpId)
- The above query uses a SELECT statement in the SET clause of the UPDATE statement.
- If the subquery finds a matching row, the update query updates the records for the specific employee.
- If the subquery returns NULL (no matching row), it updates NULL for the respective column.
- If the subquery returns more than one matched row, the UPDATE statement raises an error – “SQL Server Subquery returned more than 1 value. This is not permitted when the subquery uses comparison operators(=, !=, <, <= , >, >=).”
Subquery limitations
- The subquery with a comparison operator can include only one column name except if it used for the IN or EXISTS operator. Therefore, if we require updating multiple columns of data, we need separate SQL statements.
- You cannot use ntext, text, and image data types in the subquery.
- The subquery cannot include GROUP BY and the HAVING clause if the subquery contains an unmodified comparison operator. The unmodified comparison operator cannot use the keyword ANY or ALL.
Performance comparison between different UPDATE from SELECT statements
In this section, we’ll make the performance comparison between different UPDATE from SELECT methods. To do this, we will start by executing the SQL queries together, enabling the actual execution plan (Ctrl + M) in SQL Server Management Studio and separate them using the Go statement.
In the execution plans, I get the following data for my demo:
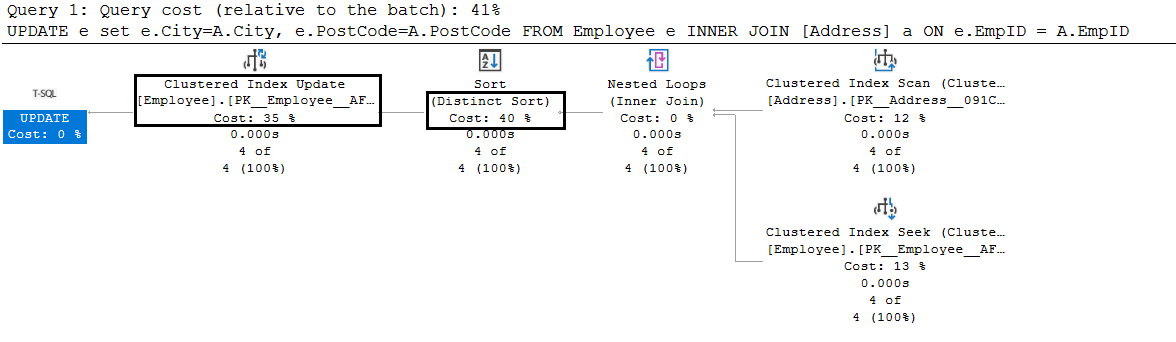
- Join Method has a 41% query cost (relative to the overall batch)
- The MERGE statement has a 34% query cost (relative to the overall batch)
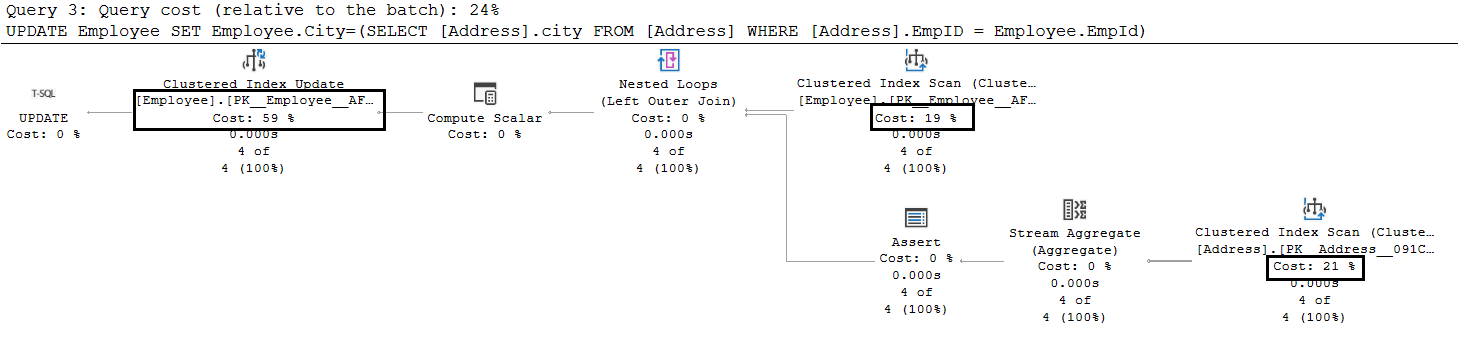
- The subquery method has a 24% query cost (relative to the overall batch)
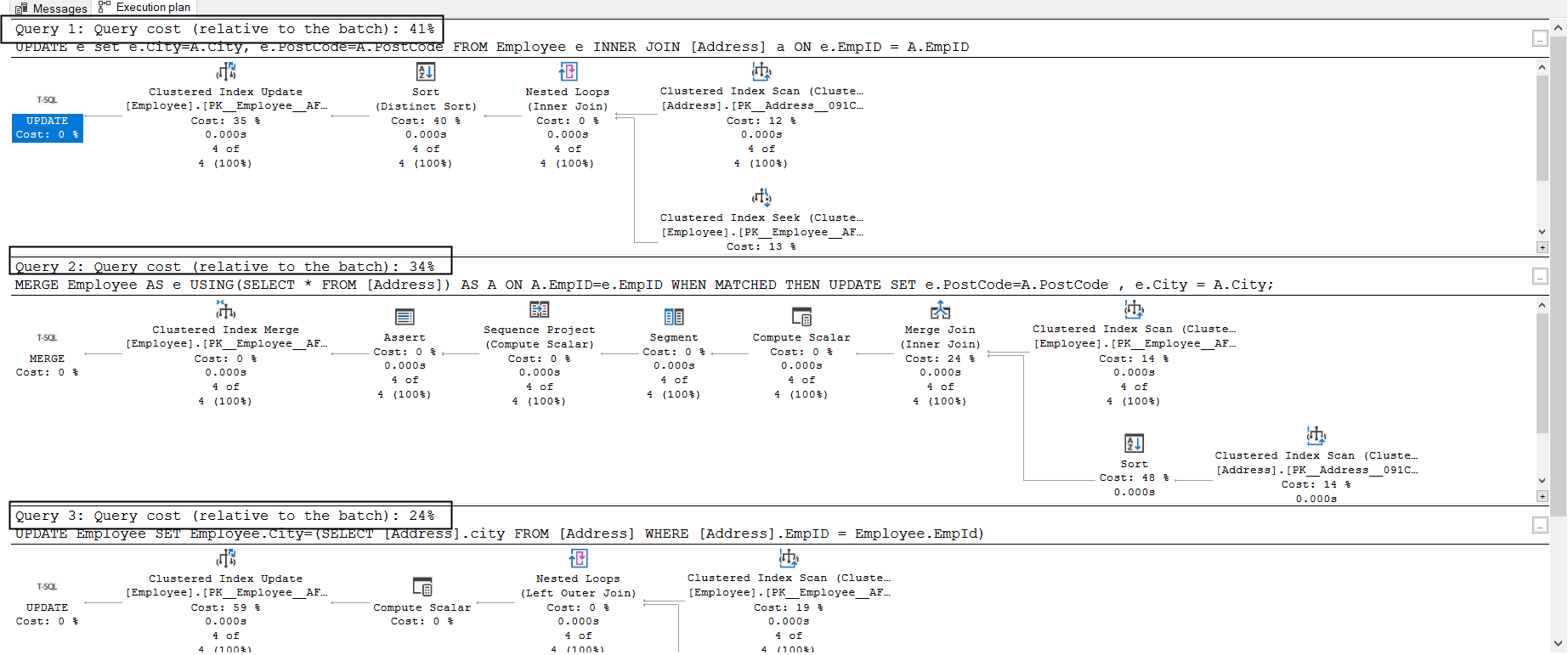
The JOIN method uses 40% cost for the distinct sort and 35% cost for clustered index update.
The merge join uses an inner join for matching data rows between the source and target data. It also has the maximum relative cost for sort operator.

The subquery is the fastest method to update column data. It uses the clustered index update and clustered index scan as highlighted.
For more details, you can refer to my previous articles: SQL Server Execution Plan — What is it and How Does it Help with Performance Problems? and How to Read and Analyze SQL Server Execution Plans.
Summary
You can use any method specified in this article for performing UPDATE from SELECT statements. The subquery works efficiently, but it has its own limitations, as highlighted earlier. The overall performance of your database depends on the table data, the number of updates, table relationships, indexes, and statistics.


