

Constraints in SQL server
Constraints in SQL Server are predefined rules that you can enforce on single or multiple columns. These constraints help maintain the integrity, reliability and accuracy of values stored in these columns. You can create constraints using CREATE TABLE or ALTER Table statements. If you use the ALTER TABLE statement, SQL Server will check the existing column data before creating the constraint.
If you insert data in the column that meets the constraint rule criteria, SQL Server inserts data successfully. However, if data violates the constraint, the insert statement is aborted with an error message.
For example, consider that you have an [Employee] table that stores your organization’s employee data, including their salary. There are a few rules of thumb when it comes to values in the salary column.
- The column cannot have negative values such as -10,000 or -15,000 USD.
- You also want to specify the maximum salary value. For example, the maximum salary should be less than 2,000,000 USD.
If you insert a new record with a constraint in place, SQL Server will validate the value against the defined rules.
Inserted value:
Salary 80,000: Inserted successfully
Salary -50,000: Error
We’ll explore the following constraints in SQL Server in this article.
- NOT NULL
- UNIQUE
- CHECK
- PRIMARY KEY
- FOREIGN KEY
- DEFAULT
NOT NULL constraint
By default, SQL Server allows storing NULL values in columns. These NULL values do not represent valid data.
For example, every employee in an organization must have an Emp ID, first name, gender and address. Therefore, you can specify a column with NOT NULL constraints to always ensure valid values.
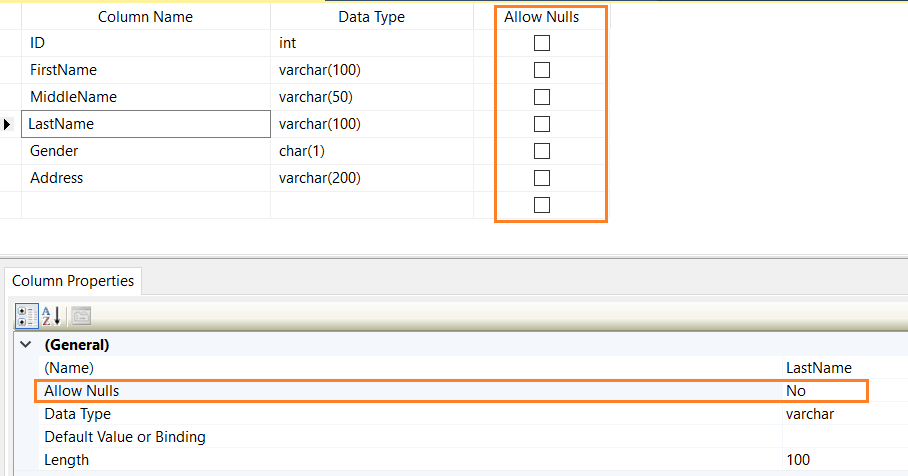
The below CREATE TABLE script defines NOT NULL constraints for [ID],[FirstName],[LastName],[Gender] and [Address] columns.
CREATE TABLE Employees ( ID INT NOT NULL, [FirstName] Varchar(100) NOT NULL, [MiddleName] Varchar(50) NULL, [LastName] Varchar(100) NOT NULL, [Gender] char(1) NOT NULL, [Address] Varchar(200) NOT NULL )
To validate the NOT NULL constraints, behavior, we use the following INSERT statements.
- Insert values for all columns (NULL and NOT NULL) – Inserts successfully
INSERT INTO Employees (ID,[FirstName],[MiddleName],[LastName],[gender],[Address]) VALUES(1,'Raj','','Gupta','M','India')
- Insert values for columns with NOT NULL property – Inserts successfully
INSERT INTO Employees (ID,[FirstName],[LastName],[gender],[Address]) VALUES(2, 'Shyam','Agarwal','M','UK')
- Skip inserting values for [LastName] column having NOT NULL constraints – Fails+
INSERT INTO Employees (ID,[FirstName],[gender],[Address]) VALUES(3,'Sneha','F','India')
The last INSERT statement raised the error – Cannot insert NULL values into the column.

This table has the following values inserted in the [Employees] table.

Suppose that we do not require NULL values in the [MiddleName] column as per HR requirements. For this purpose, you can use the ALTER TABLE statement.
ALTER TABLE Employees ALTER COLUMN [MiddleName] VARCHAR(50) NOT NULL
This ALTER TABLE statement fails because of the existing values of the [MiddleName] column. To enforce the constraint, you need to eliminate these NULL values and then run the ALTER statement.
UPDATE Employees SET [MiddleName]='' WHERE [MiddleName] IS NULL Go ALTER TABLE Employees ALTER COLUMN [MiddleName] VARCHAR(50) NOT NULL
You can validate the NOT NULL constraints using the SSMS table designer as well.
UNIQUE constraint
The UNIQUE constraint in SQL Server ensures that you do not have duplicate values in a single column or combination of columns. These columns should be part of the UNIQUE constraints. SQL Server automatically creates an index when UNIQUE constraints are defined. You can have only one unique value in the column (including NULL).
For example, create the [DemoTable] with the [ID] column having UNIQUE constraint.
CREATE TABLE DemoTable ( [ID] INT UNIQUE NOT NULL, [EmpName] VARCHAR(50) NOT NULL )
Then, expand the table in SSMS, and you have a unique index (Non-Clustered), as shown below.
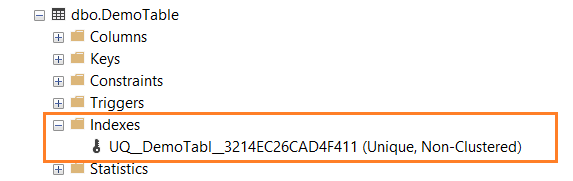
Please right-click on the index and generate its script. As shown below, it uses ADD UNIQUE NONCLUSTERED keyword for the constraint.

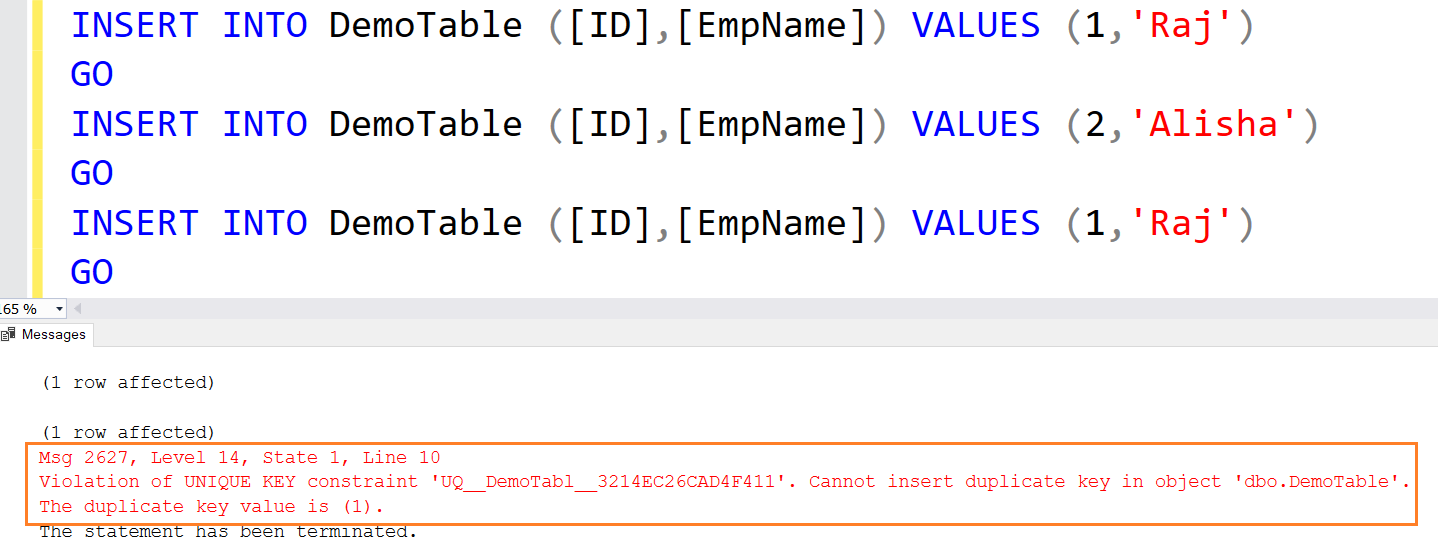
The following insert statement gives an error because it tries to insert duplicate values.
INSERT INTO DemoTable ([ID],[EmpName]) VALUES (1,'Raj') GO INSERT INTO DemoTable ([ID],[EmpName]) VALUES (2,'Alisha') GO INSERT INTO DemoTable ([ID],[EmpName]) VALUES (1,'Raj') GO
CHECK constraint
The CHECK constraint in SQL Server defines a valid range of values that can be inserted into specified columns. It evaluates each inserted or modified value, and if it is satisfied, the SQL statement is completed successfully.
The following SQL script places a constraint for the [Age] column. Its value should be greater than 18 years.
CREATE TABLE DemoCheckConstraint ( ID INT PRIMARY KEY, [EmpName] VARCHAR(50) NULL, [Age] INT CHECK (Age>18) ) GO
Let’s insert two records in this table. The query inserts the first record successfully.
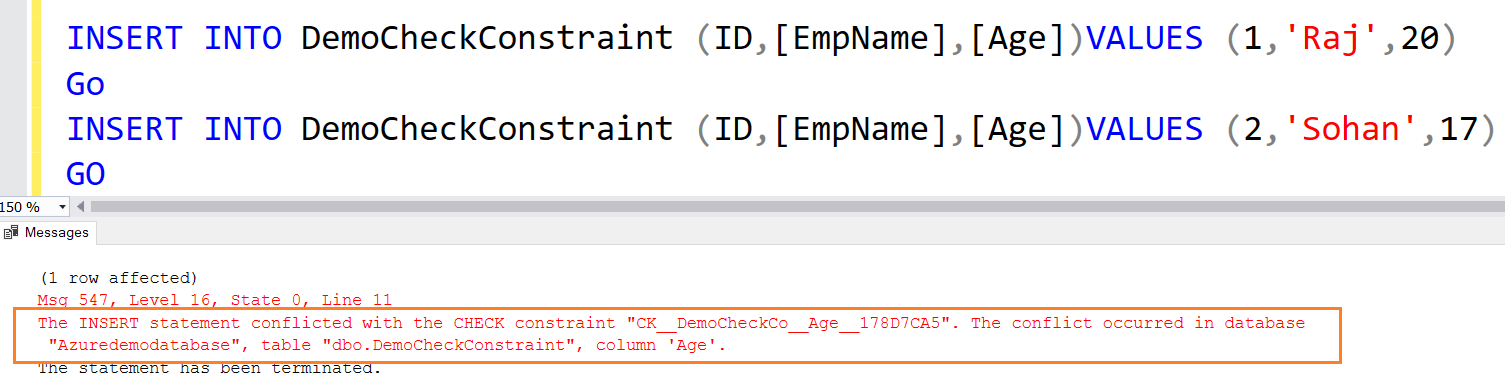
INSERT INTO DemoCheckConstraint (ID,[EmpName],[Age])VALUES (1,'Raj',20) Go INSERT INTO DemoCheckConstraint (ID,[EmpName],[Age])VALUES (2,'Sohan',17) GO
The second INSERT statement fails because it does not satisfy the CHECK constraint condition.
Another use case for the CHECK constraint is to store valid values of Zip codes. In the below script, we add a new column [ZipCode] and it uses the CHECK constraint to validate the values.
ALTER TABLE DemoCheckConstraint ADD zipcode int
GO
ALTER TABLE DemoCheckConstraint
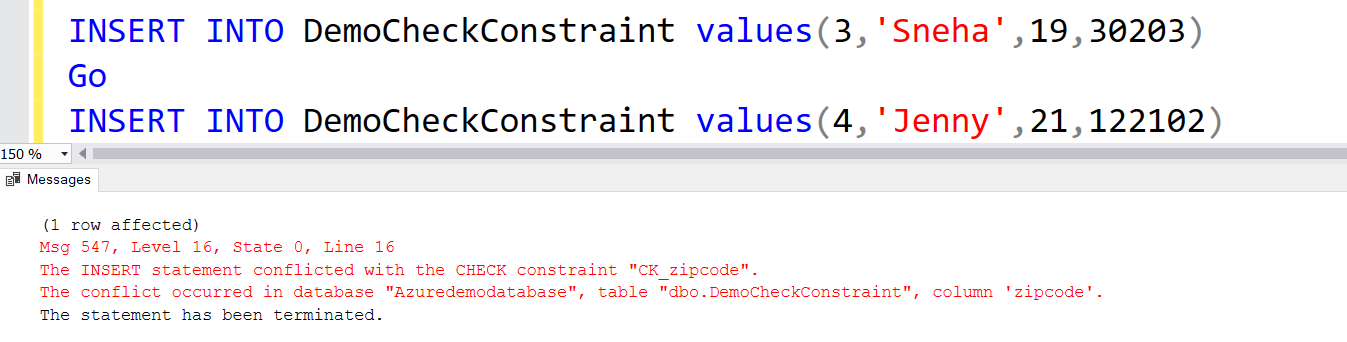
ADD CONSTRAINT CK_zipcode CHECK (zipcode LIKE REPLICATE ('[0-9]', 5))This CHECK constraint does not allow invalid Zip codes. For example, the second INSERT statement generates an error.
INSERT INTO DemoCheckConstraint values(3,'Sneha',19,30203) Go INSERT INTO DemoCheckConstraint values(4,'Jenny',21,122102)
PRIMARY KEY constraint
The PRIMARY KEY constraint in SQL Server is a popular choice among database professionals for implementing unique values in a relational table. It combines UNIQUE and NOT NULL constraints. SQL Server automatically creates a clustered index once we define a PRIMARY KEY constraint. You can use a single column or a set of combinations for defining unique values in a row.
Its primary purpose is to enforce the integrity of the table using the unique entity or column value.
It is similar to the UNIQUE constraint with the following differences.
| PRIMARY KEY | UNIQUE KEY |
| It uses a unique identifier for each row in a table. | It uniquely defines values in a table column. |
| You cannot insert NULL values in the PRIMARY KEY column. | It can accept one NULL value in the unique key column. |
| A table can have only one PRIMARY KEY constraint. | You can create multiple UNIQUE KEY constraints in SQL Server. |
| By default, it creates a clustered index for the PRIMARY KEY columns. | The UNIQUE KEY creates a non-clustered index for the primary key columns. |
The following script defines the PRIMARY KEY on the ID column.
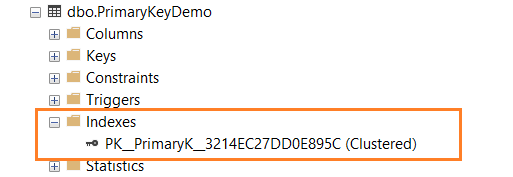
CREATE TABLE PrimaryKeyDemo ( ID INT PRIMARY KEY, [Name] VARCHAR(100) NULL )
As shown below, you have a clustered key index after defining the PRIMARY KEY on the ID column.
Let’s insert the records into the [PrimaryKeyDemo] table with the following INSERT statements.
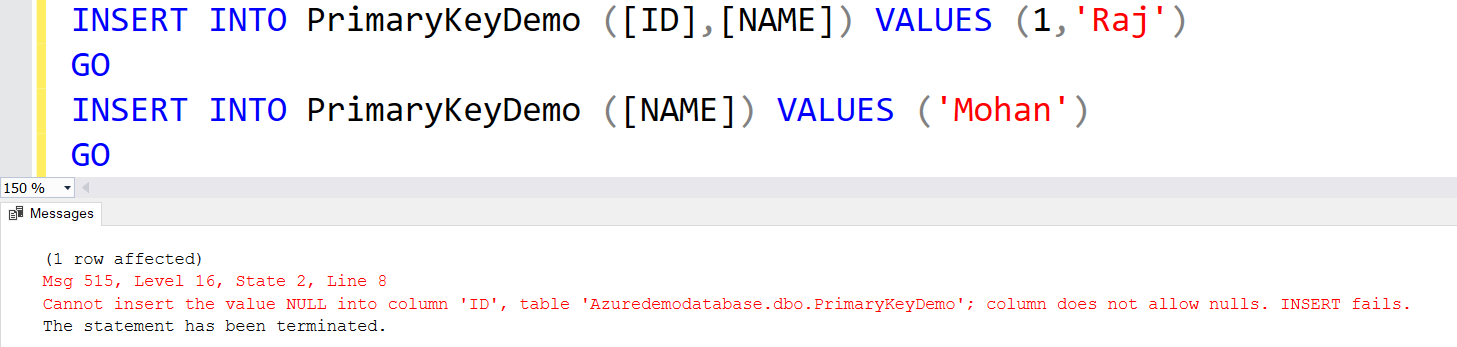
INSERT INTO PrimaryKeyDemo ([ID],[NAME]) VALUES (1,'Raj')
GO
INSERT INTO PrimaryKeyDemo ([NAME]) VALUES ('Mohan')
GOYou get an error in the second INSERT statement because it tries to insert the NULL value.
Similarly, if you try to insert duplicate values, you get the following error message.

FOREIGN KEY constraint
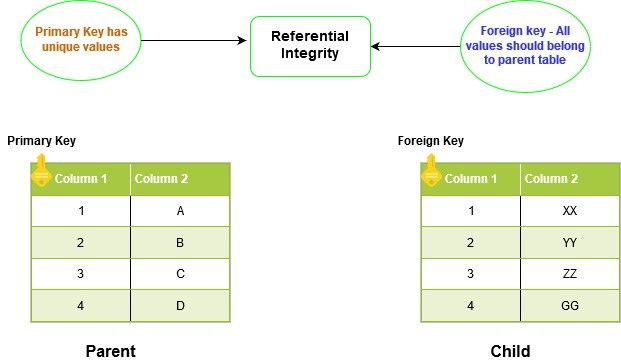
The FOREIGN KEY constraint in SQL Server creates relationships between two tables. This relationship is known as the parent-child relationship. It enforces referential integrity in SQL Server.
The child table foreign key should have a corresponding entry in the parent primary key column. You cannot insert values in the child table without inserting it in the parent table first. Similarly, first, we need to remove the value from the child table before it can be dropped from the parent table.
Since we cannot have duplicate values in the PRIMARY KEY constraint, it does not allow duplicate or NULL in the child table as well.
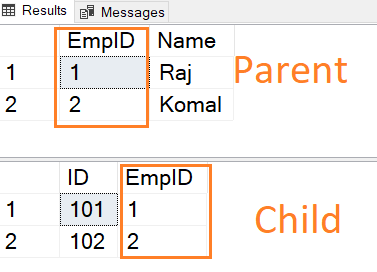
The following SQL script creates a parent table with a primary key and a child table with a primary and foreign key reference to the parent table [EmpID] column.
CREATE TABLE ParentTable ( [EmpID] INT PRIMARY KEY, [Name] VARCHAR(50) NULL ) GO CREATE TABLE ChildTable ( [ID] INT PRIMARY KEY, [EmpID] INT FOREIGN KEY REFERENCES ParentTable(EmpID) )
Insert records in both tables. Note that the child table foreign key value has an entry in the parent table.
INSERT INTO ParentTable VALUES (1,'Raj'),(2,'Komal') INSERT INTO ChildTable VALUES (101,1),(102,2)
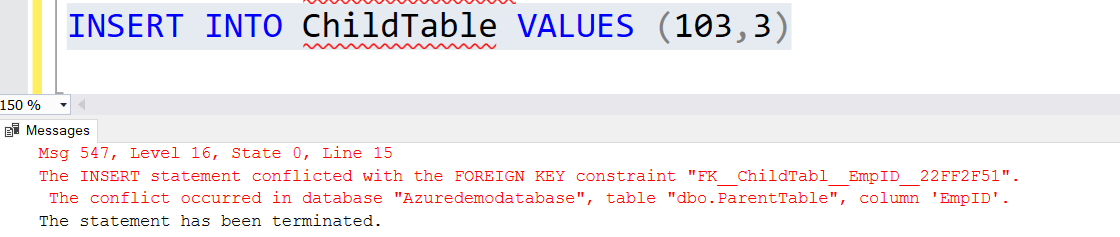
If you try to insert a record directly in the child table that does not reference the parent table’s primary key, you get the following error message.
DEFAULT constraint
The DEFAULT constraint in SQL Server provides the default value for a column. If we do not specify a value in the INSERT statement for the column with the DEFAULT constraint, SQL Server uses its default assigned value. For example, suppose an order table has records for all customers orders. You can use the GETDATE() function to capture the order date without specifying any explicit value.
CREATE TABLE Orders ( [OrderID] INT PRIMARY KEY, [OrderDate] DATETIME NOT NULL DEFAULT GETDATE() ) GO
To insert the records in this table, we can skip assigning values for the [OrderDate] column.
INSERT INTO Orders([OrderID]) values (1) GO
SELECT * FROM Orders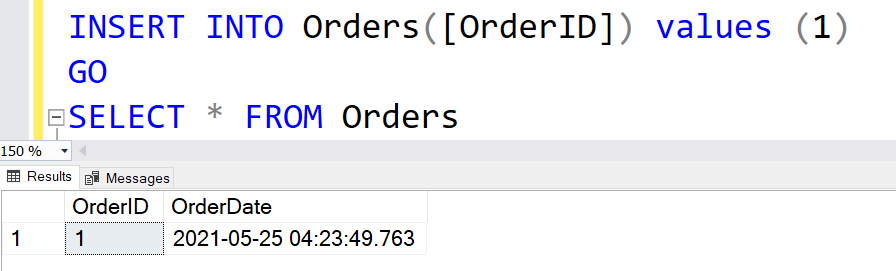
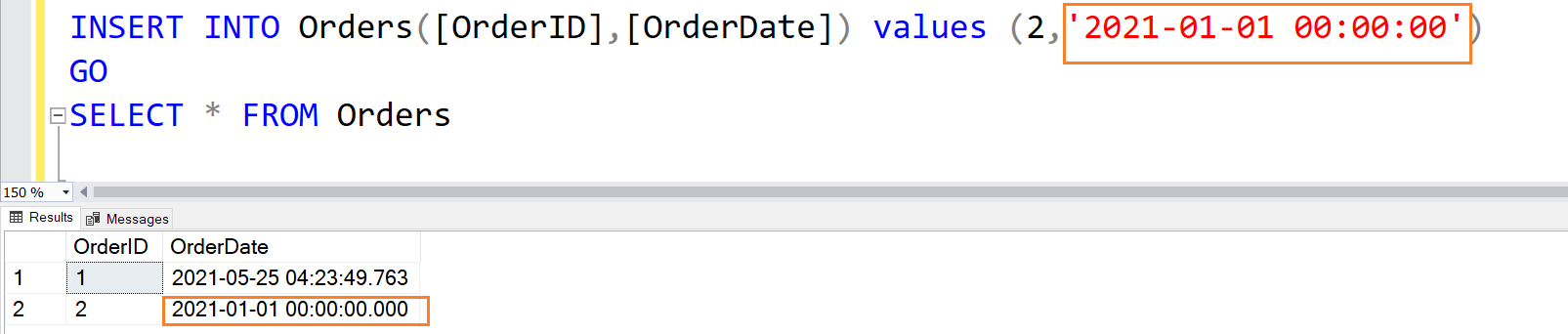
Once the DEFAULT constraint column specifies an explicit value, SQL Server stores this explicit value instead of the default value.
Constraint benefits
The constraints in SQL Server can be beneficial in the following cases:
- Enforcing business logic
- Enforcing referential integrity
- Preventing storing improper data in SQL Server tables
- Enforcing uniqueness for column data
- Improving query performance as the query optimizer is aware of unique data and validates sets of values
- Preventing storing NULL values in SQL tables
- Writing codes to avoid NULL while displaying data in the application


