
This post is the second in a series on data lakehouses, expanding on the key insights shared in “Data lakehouse benefits: Why enterprises are choosing this modern data architecture”. In that article, we explored the reasons behind the rapid adoption of lakehouse platforms and how they blend the flexibility of data lakes with the governance of warehouses. Now, we’re going deeper—into strategy, execution and how you can turn a data lakehouse architecture into a business advantage.
Expectations have evolved—has your data strategy kept up?
If you’re leading data strategy today, you’re under pressure to do more than generate reports. Your stakeholders expect real-time insights, AI-ready data pipelines and a foundation that can evolve with shifting market demands. Traditional data warehouses weren’t built for this. They’re too rigid, too slow and too disconnected from the modern pace of business. And data lakes fall short when it comes to delivering the governance, speed and query efficiency required for advanced analytics and machine learning in the enterprise.
What you need now is an agile, scalable data lakehouse strategy. A modern data lakehouse doesn’t just consolidate storage and compute. It helps you respond faster to change, support smarter decision-making and turn data into a competitive asset.
Here’s a chart that illustrates the evolution of the unified data platform architectures:
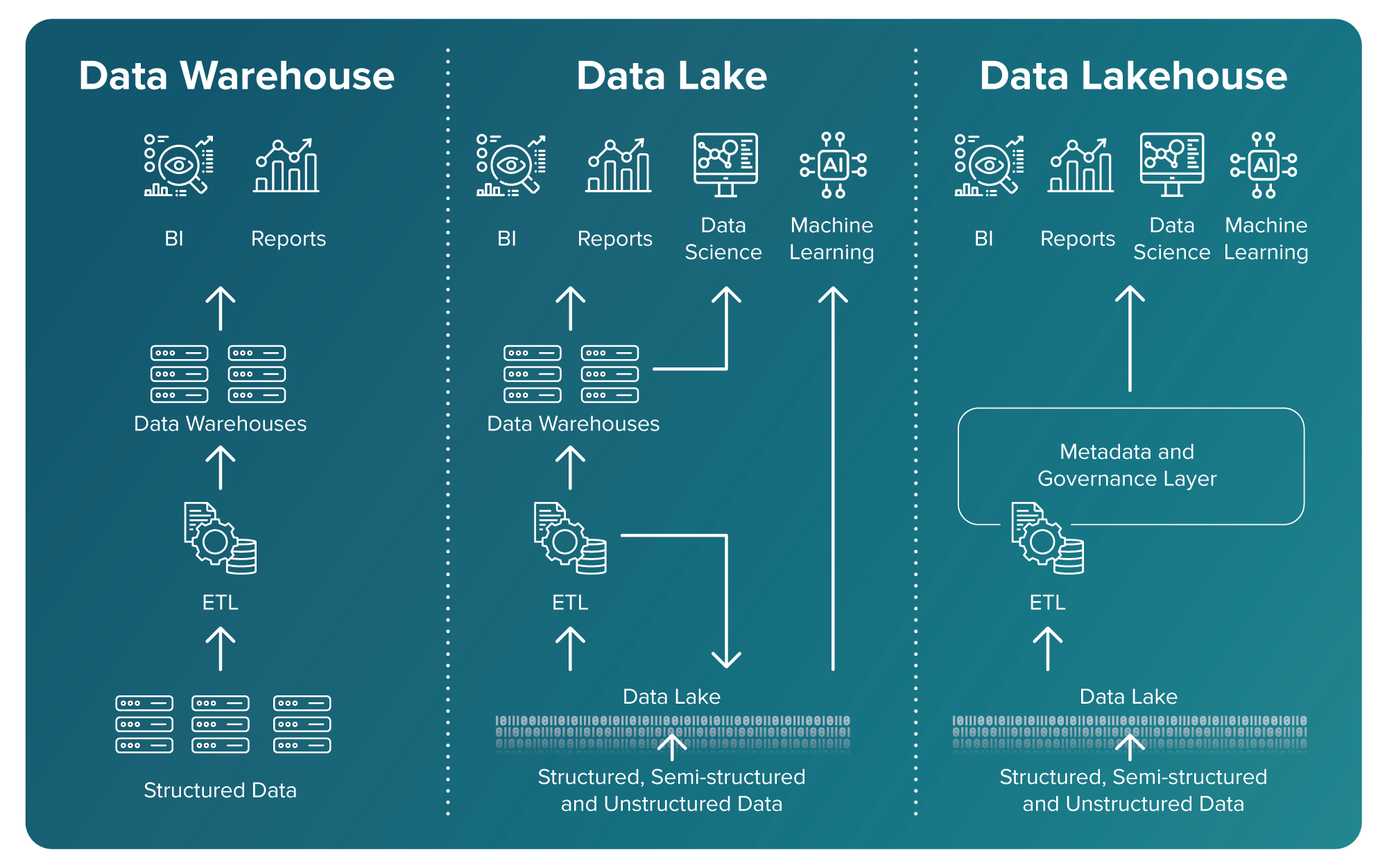
This guide walks you through what’s driving adoption, how lakehouses solve critical challenges and what to prioritize as you modernize.
Why traditional platforms are holding you back
Your legacy data warehouse might still run standard reports. But when you’re trying to feed machine learning models, integrate unstructured content or deliver insights on demand, cracks start to show. You’ve likely run into one or more of these issues:
- Rigid schemas that slow down new use cases
- ETL processes that can’t keep up with real-time data demands
- Multiple versions of the truth across siloed systems
- Difficulty supporting semi-structured or unstructured data like images, PDFs or logs
- Governance and lineage gaps that compromise trust in data
These challenges aren’t just technical. They have direct business impact. Slow data pipelines delay decision-making. Poor lineage leads to rework. A lack of agility prevents your teams from taking full advantage of AI and advanced analytics.
How a data lakehouse strategy closes the gap
A data lakehouse brings together the best of both worlds. It offers the flexibility and scalability of a data lake with the structure and performance of a data warehouse. That means you can ingest raw data at scale and still support governed, fast queries for both BI and ML use cases.
Here’s how the capabilities of the three architectures stack up:
| Feature | Data Warehouse | Data Lake | Data Lakehouse |
| Purpose | BI, reporting | Raw data storage | Unified analytics |
| Data types | Structured | All types | All types |
| Storage cost | High | Low | Medium |
| Performance | High (for SQL, BI) | Variable | High |
| Schema | Schema-on-write | Schema-on-read | Flexible schema |
| Governance | Mature | Basic | Improving |
| Data processing | Batch | Batch & real-time | Batch & real-time |
| AI/ML support | Limited | Strong | Strong |
| Tools | Traditional BI | Big data and ML | Both BI and ML |
With the right lakehouse strategy, you can:
- Support all data types: structured, semi-structured and unstructured
- Serve data to both people and machines without duplication
- Enable real-time analytics and machine learning at production scale
- Reduce costs by consolidating storage and compute infrastructure
- Establish consistent governance and semantic modeling across domains
A data lakehouse is a more flexible and future-ready data architecture—one that doesn’t force you to choose between speed and trust.
Why now is the time to modernize
You’re not rebuilding from scratch. You’re dealing with complex environments: legacy systems, siloed tools, disconnected pipelines and growing pressure to deliver faster insights. A data lakehouse strategy doesn’t require you to rip and replace your stack overnight. It gives you a roadmap for evolving your architecture at your own pace.
You can start small by offloading select use cases to a modern platform. Keep your warehouse for financial reporting, but use your lakehouse for real-time product feedback, customer personalization or advanced analytics. As you gain confidence, you can expand and consolidate. This hybrid, layered approach lets you build incrementally while reducing risk.
How organizations are seeing value
Forward-looking companies are already realizing benefits by shifting to a lakehouse strategy. Here are a few examples:
- A regional insurer cut processing time by 45% and improved audit readiness by unifying scanned documents, transcripts and claim data
- A global retailer boosted forecast accuracy and reduced inventory costs by training ML models on unified data sets from sales, reviews and foot traffic
- A healthcare provider enabled faster regulatory reporting and AI-driven clinical insights by consolidating siloed systems into a single, governed layer
These aren’t just efficiency wins. They’re examples of how a smart data lakehouse strategy drives measurable business outcomes.
How to evaluate your data readiness
Before you implement a lakehouse, take a close look at your current environment. Ask yourself:
- Where are your pipelines fragile or overly complex?
- Which processes rely on stale or inconsistent data?
- What domains lack clear semantic definitions?
- How easily can your architecture support new data types?
- Do you have visibility into lineage, access and transformations?
You don’t need all the answers today. But you do need a roadmap for how to evolve. A good lakehouse strategy begins with clear priorities—like improving observability, standardizing definitions or streamlining access controls.
What to look for in a modern platform
Your technology decisions will shape your lakehouse success. While many vendors claim lakehouse capabilities, not all platforms are equal. Here’s what to prioritize:
- Support for all data types: Make sure your platform handles structured, semi-structured and unstructured data natively
- Open formats and interoperability: Avoid lock-in by choosing tools that support open standards and play well with your existing stack
- Lineage and governance: Look for built-in features that help you track where data came from, how it changed and who accessed it
- Real-time performance: Whether it’s streaming IoT data or updating ML features hourly, your platform needs to support fast, continuous ingestion and query performance
- Semantic modeling: You need more than raw data—you need meaning. A strong semantic layer allows teams to align on shared definitions and reduce confusion across reports and models
Here’s a high-level overview of four of the major lakehouse platforms:
| Capability / Use Case | Snowflake | Databricks | BigQuery | Fabric |
| Data storage (structured/unstructured) | ✅ | ✅ | ✅ | ✅ |
| Open format support | ⚠️ | ✅ | ⚠️ | ✅ |
| Real-time analytics | ✅ | ✅ | ✅ | ✅ |
| ML/AI integration | ⚠️ | ✅ | ✅ | ⚠️ |
| Governance & lineage | ✅ | ⚠️ | ✅ | ✅ |
| Semantic modeling | ✅ | ⚠️ | ⚠️ | ✅ |
| Multi-cloud support | ✅ | ✅ | ✅ | ⚠️ |
| Built-in data catalog | ✅ | ⚠️ | ✅ | ✅ |
LEGEND: ✅ = Strong support | ⚠️ = Partial support | ❌ = No support
Different platforms have different strengths. The key is choosing the one that aligns with your use cases, skills and long-term goals.
How to take the first steps
You don’t need a massive overhaul to begin. You can:
- Audit your data workflows: Identify high-friction areas where data is slow, unreliable or hard to trace
- Prioritize your use cases: Focus on those where flexibility, speed or trust are most critical
- Design a semantic layer: Start defining shared concepts like “customer,” “product” or “region” to ensure consistency
- Involve your teams: Bring analytics, engineering and governance teams together early to align on priorities
- Pick a pilot: Choose a low-risk but high-impact initiative to prove out your new architecture
Your lakehouse doesn’t have to be perfect on day one. It just needs to move you in the right direction.
Why your future depends on it
Every organization is under pressure to deliver faster insights, better models and more flexible data services. Whether you’re powering next-best-action models, AI copilots or regulatory analytics, your underlying data architecture matters.
With a strong data lakehouse strategy, you’re not just solving today’s pain points. You’re preparing for what comes next. You’re enabling cross-functional teams to collaborate on a shared platform. You’re reducing the cost of complexity. And you’re making your data ready for whatever the business demands next.
So don’t wait for a breaking point. Build your strategy now—layer by layer—with clarity, flexibility and scale in mind. Because your ability to deliver real-time, trusted and AI-ready insights depends on it.


