

This article will cover Postgres indexes and the various index types supported.
Indexes play a vital role in the query performance of any relational database. The index provides feasibility to access the data pages directly. It is similar to an index section of a book where you can directly jump to a specific page by referencing the index’s keyword. Imagine a book without an index. If you require information about a keyword, you would need to scan every single page.
There are various type of indexes. Postgres supports the following index types.
- B-Tree
- Hash
- GiST
- SP-GiST
- GIN
- BRIN
It is essential to know which Postgres index to create in order to gain the right performance benefits. Let’s explore all the Postgres index types and their specific use cases.
B-tree indexes
B-tree is the default index in Postgres and is best used for specific value searches, scanning ranges, data sorting or pattern matching. If we don’t specify any particular index type in the CREATE INDEX command, Postgres creates a B-tree index which follows the Lehman & Yao Algorithm and B+-Trees.
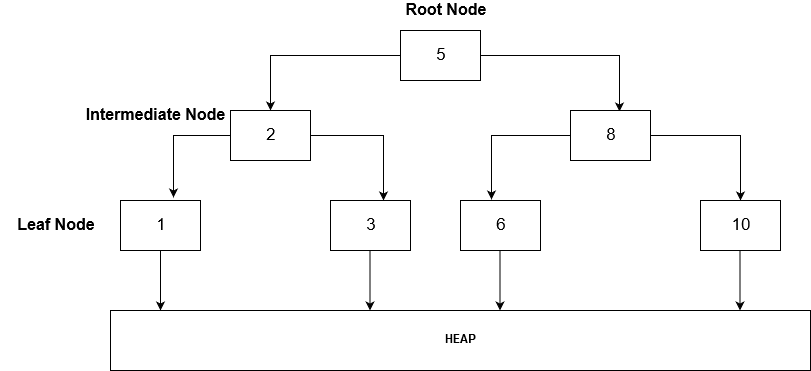
At a high-level, the B-tree has Root, Intermediate and Leaf node.
- The Root node and intermediate node contain keys and points to the lower level nodes.
- The Leaf node contains keys as well as data points to the heap.
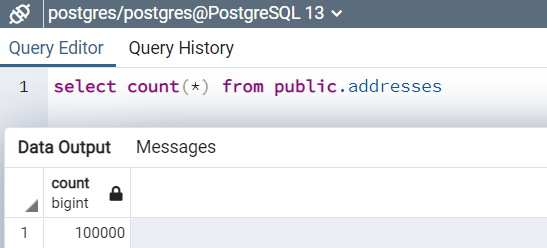
For this demo, I created a “public”.”addresses” table using the GitHub reference link. This table has 100,000 rows.
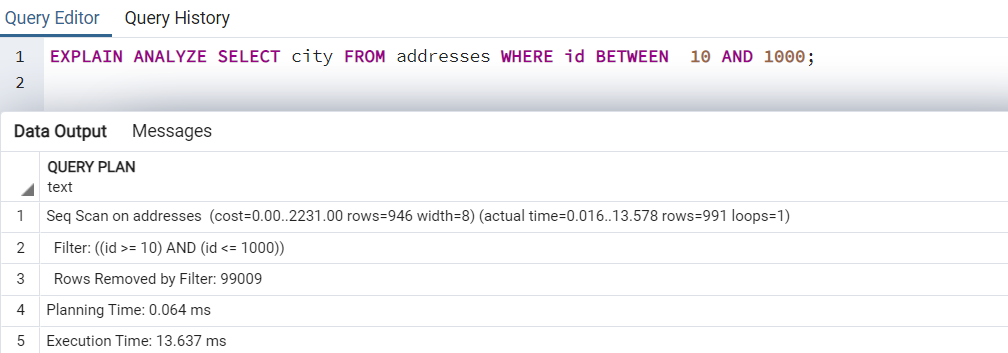
Currently, the [addresses] table does not have an index on it. Therefore, if we generate an execution plan of the SELECT statement, it performs a sequence scan.
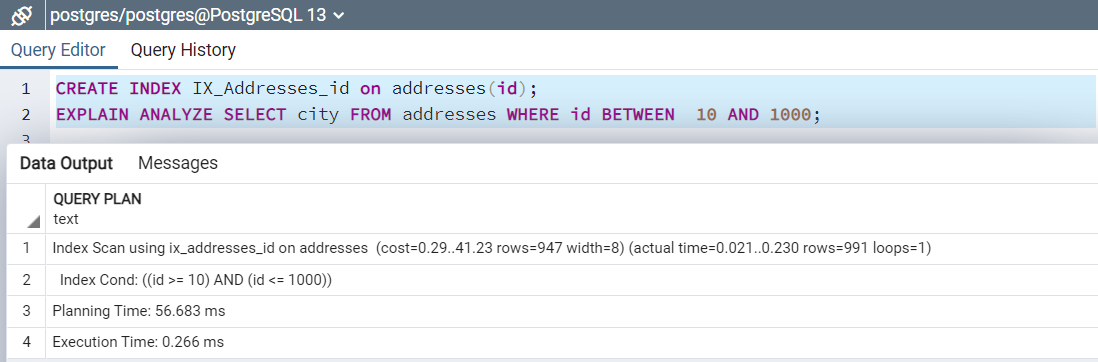
Postgres automatically creates a B-tree index if we define a primary or unique key on a table. You can also define the index on multiple columns (composite key) as well. For this demo, let’s use the CREATE INDEX statement and define an index on the ID column.
CREATE INDEX IX_Addresses_id on addresses(id); EXPLAIN ANALYZE SELECT city FROM addresses WHERE id BETWEEN 10 AND 1000;
Once Postgres creates a B-tree index on the ID column, it improves the performance.
- Query execution took 0.266ms with an index in comparison to 13.637ms without an index.
- It uses the index scan in comparison to sequence scan that is a costly operator.
Hash index
Hash indexes are best suited to work with equality operators. The equality operator looks for the exact match of data. Starting from Postgres 9.x version, the hash indexes are WAL-logged and crash-safe.
In the following CREATE INDEX statement, we create a hash index on the “City” column ( Using HASH(“City”).
CREATE INDEX IX_Addresses_city on addresses using HASH("city");Now, let’s look for records from the addresses whose city equals ZQ.
EXPLAIN ANALYZE SELECT city FROM addresses WHERE city = ('ZQ')The SELECT statement uses the hash index because we have specified the equality operator.
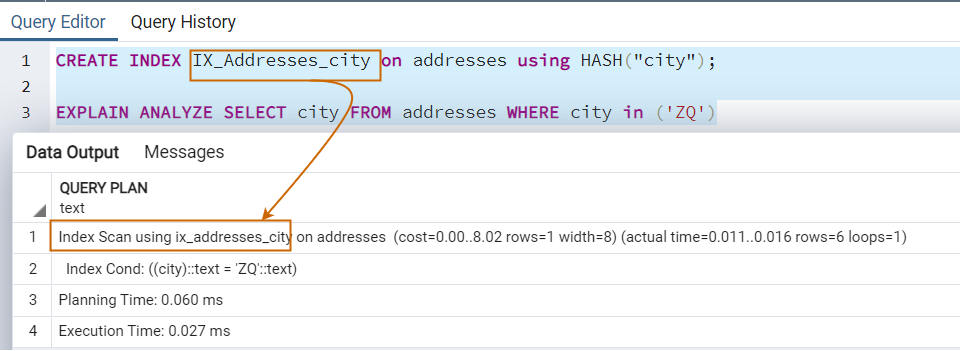
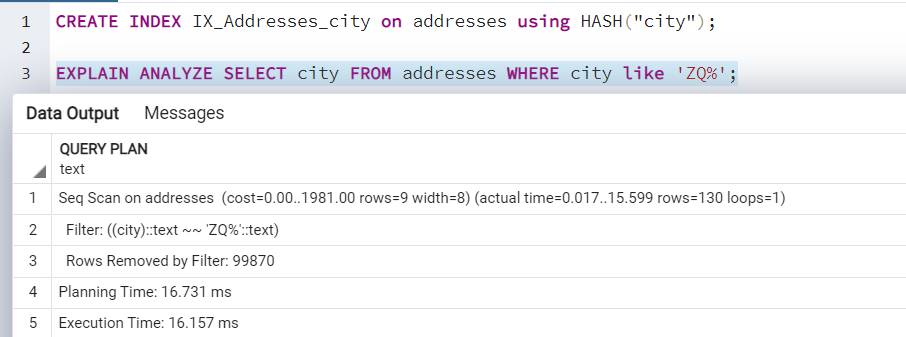
As stated above, the hash index works with an equality operator. If we specify a separate operator such as (pattern matching), it does not use the hash index as shown in the following image. Therefore, you should create this index if your workload requires many searches based on data equality.
GiST indexes
The Generalized Search Tree (GiST) is balanced, and it implements indexing schemes for new data types in a familiar balanced tree structure. It can index complex data such as geometric data and network address data. It can also implement different strategies such as B-tree or R-tree as well.
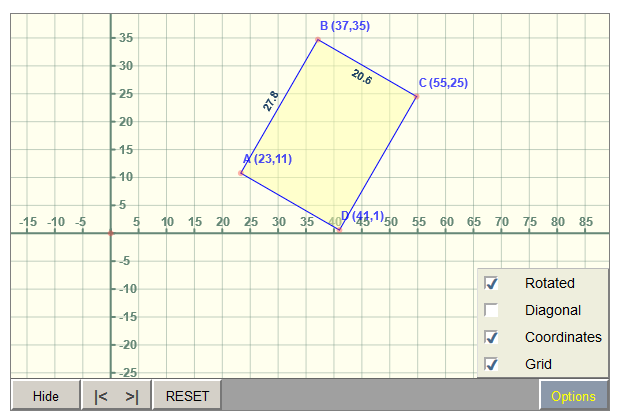
For example, in the below query, we create a [demodata] table to store point data type. It defines the point on a plane.
I suggest you reference my previous article: Exploring the Various Postgres Data Types to become more familiar with different data types.
Create table demodata ( p point); insert into demodata(p) values (point '(23,11)'), (point '(37,35)'), (point '(41,1)'), (point '(55,25)');
In this table, I store the coordinates of a rectangle. To do this, I use mathopenref for drawing the rectangle and determine its coordinates.
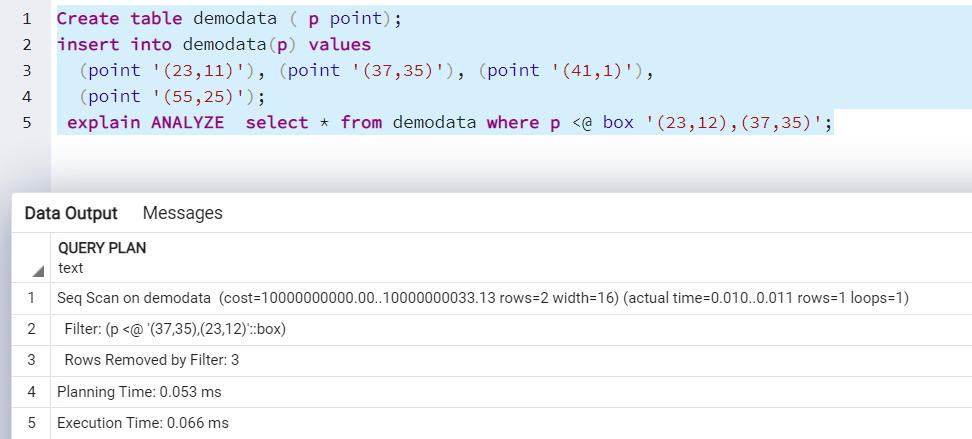
If we do not create a Postgres indexes and search for points in a rectangle, it goes through a sequence scan.
explain ANALYZE select * from demodata where p <@ box '(23,12),(37,35)';
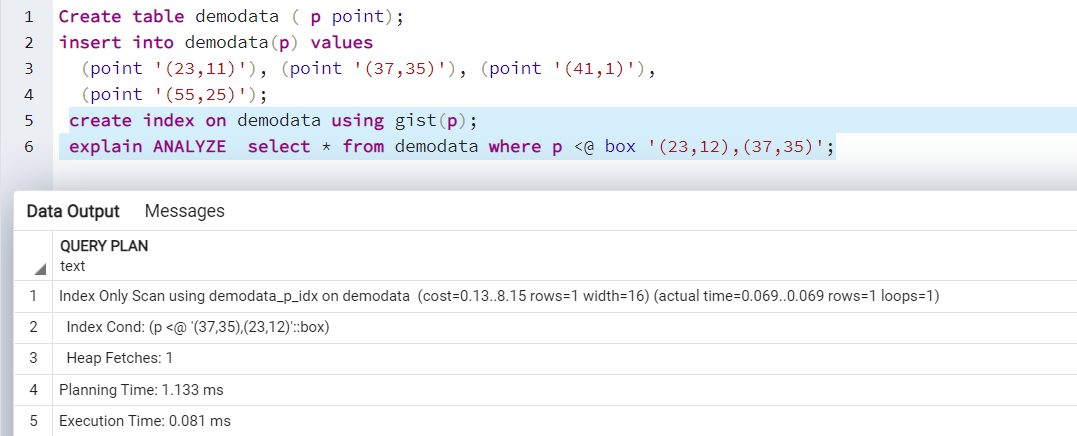
Now, we define a GiST index and rerun the SELECT statement.
create index on demodata using gist(p); explain ANALYZE select * from demodata where p <@ box '(23,12),(37,35)';
It uses the GiST index scan for retrieving the results.
SP-GiST indexes
The SP-GiST index refers to a space partitioned GiST index. It is useful for indexing non-balanced data structures using the partitioned search tree.
It is best suited for overlapping geometries and heterogeneous distributions. It can implement various trees such as quad-trees, k-d trees, and radix trees.
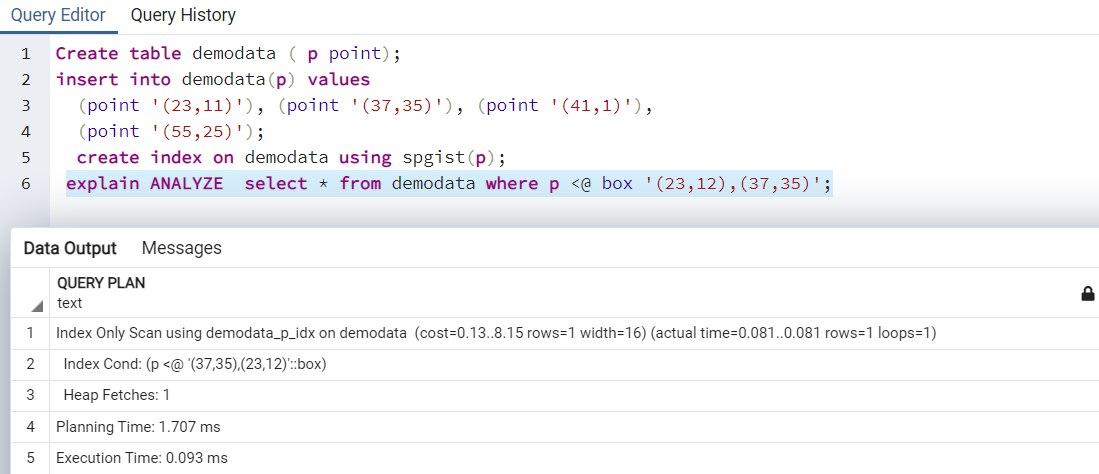
In the below example, we create the SP-GiST index on the demodata table for finding coordinates in a rectangle.
Create table demodata ( p point); Insert into demodata(p) values (point '(23,11)'), (point '(37,35)'), (point '(41,1)'), (point '(55,25)'); Create index on demodata using spgist(p); explain ANALYZE select * from demodata where p <@ box '(23,12),(37,35)';
GIN indexes
The Generalized Inverted Index (GIN) is beneficial for indexing columns that have composite types. It is best suited for data types such as JSONB, Array, Range types and full-text search.
Suppose you have a directory database where users can search the database using partial matches. For example, if a user puts a search string “raj,” it should return all rows for names such as Rajendra, Raju and Hansraj. In this instance, we can implement the GIN index for executing performance-optimized queries.
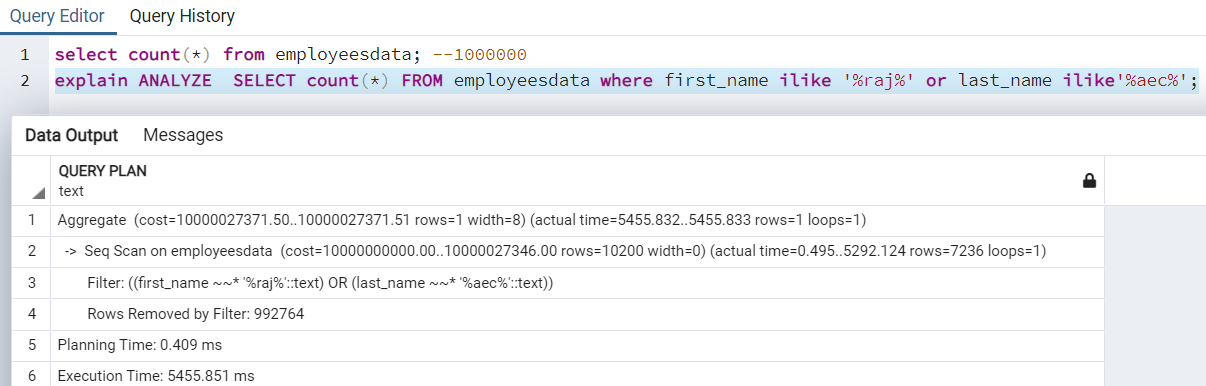
For the demonstration, I have a [employeesdata] table with 1,000,000 rows in it. It has two columns, first_name and last_name. Suppose users want to get a record count of all whose first name is like %raj%, and the last name is like ‘%aec%.
If we run the SELECT statement without creating any indexes, it takes around 5455ms for data retrieval.
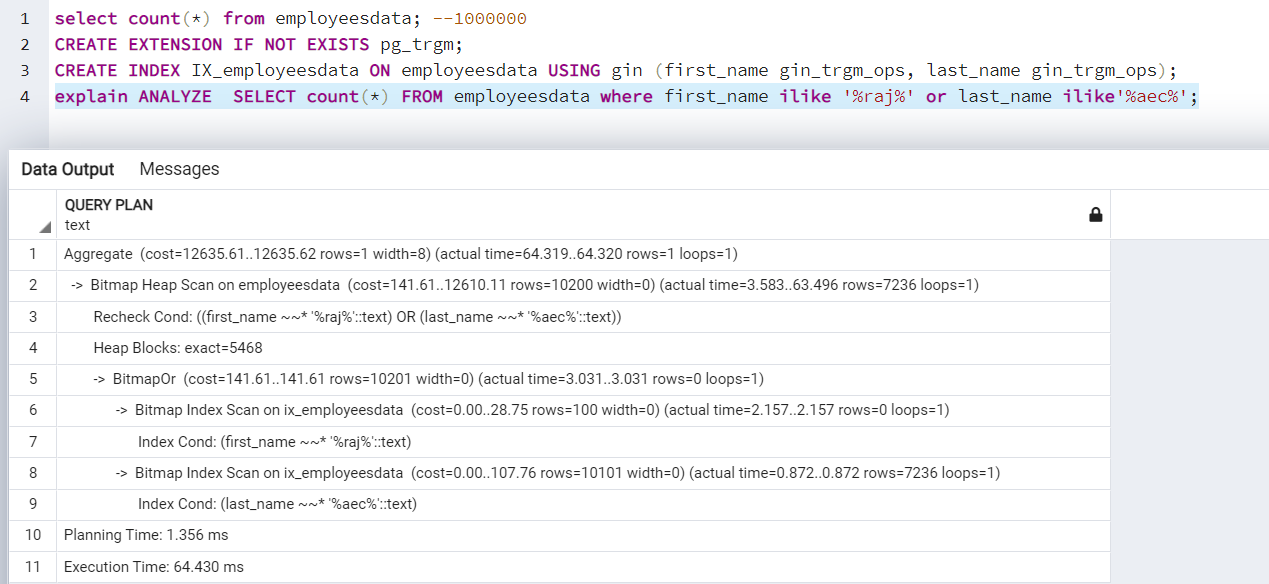
Now, if we create the GIN index on the first_name and last_name columns using the gin_trms_ops option, it instructs Postgres to use trigrams over our selected columns.
Once we rerun the query after implementing the GIN index, it is quicker. It retrieves results in 64ms in comparison to 5455ms (without an index).
BRIN index
The BRIN index is also known as Block Range Index. It stores the summary of blocks (minimum value, maximum value and page number). Once a BRIN index is implemented, it uses the BRIN values for validating each page. In case the page is not modified, its BRIN value remains the same. Now, once we specify a query to retrieve the result, it uses the minimum and maximum value range to check whether the page satisfied the result set. It is useful for extensive data such as timestamps and temperature sensor data. It also uses less storage compared to a B-tree index.
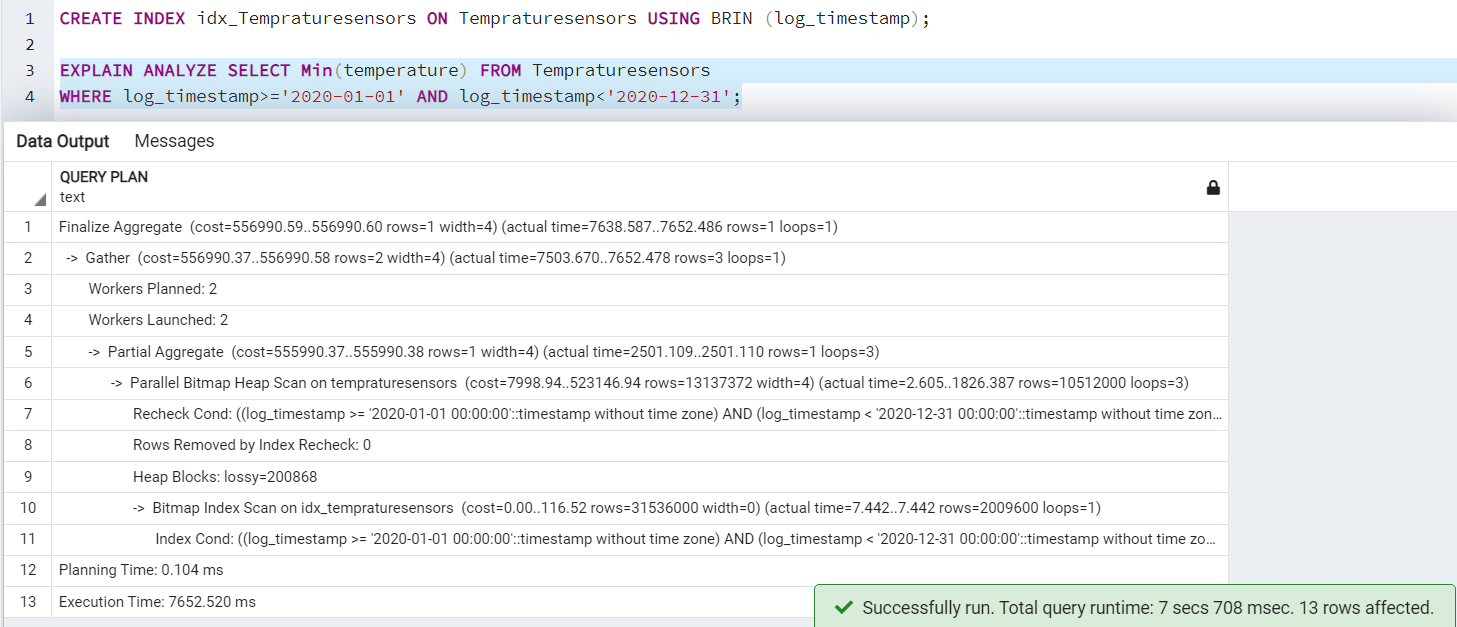
I have a table [Tempraturesensors] with approximately 3 billion rows in it. Now, suppose we require the minimum temperature for a specific date range. It takes 16083ms for data retrieval without creating any indexes.
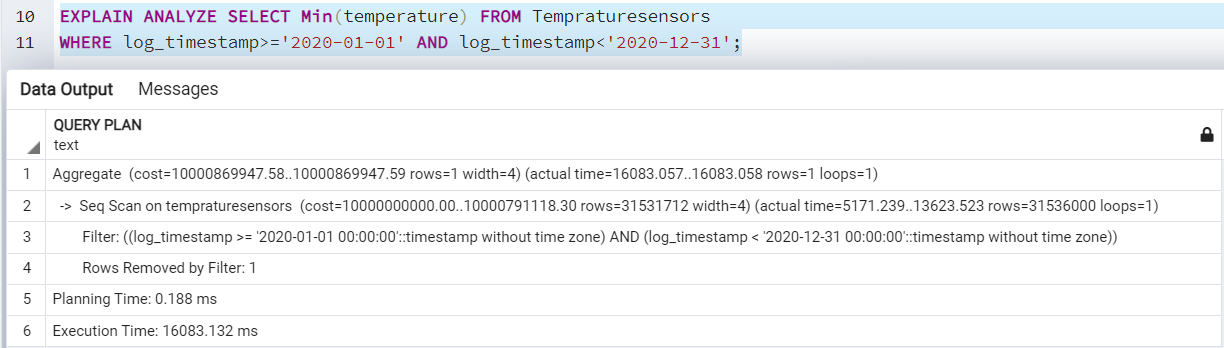
Once we create the BRIN index and re-execute the query, it gives us the result quickly. It returns results in 7652ms in comparison to 16083ms in data retrieval without an index.
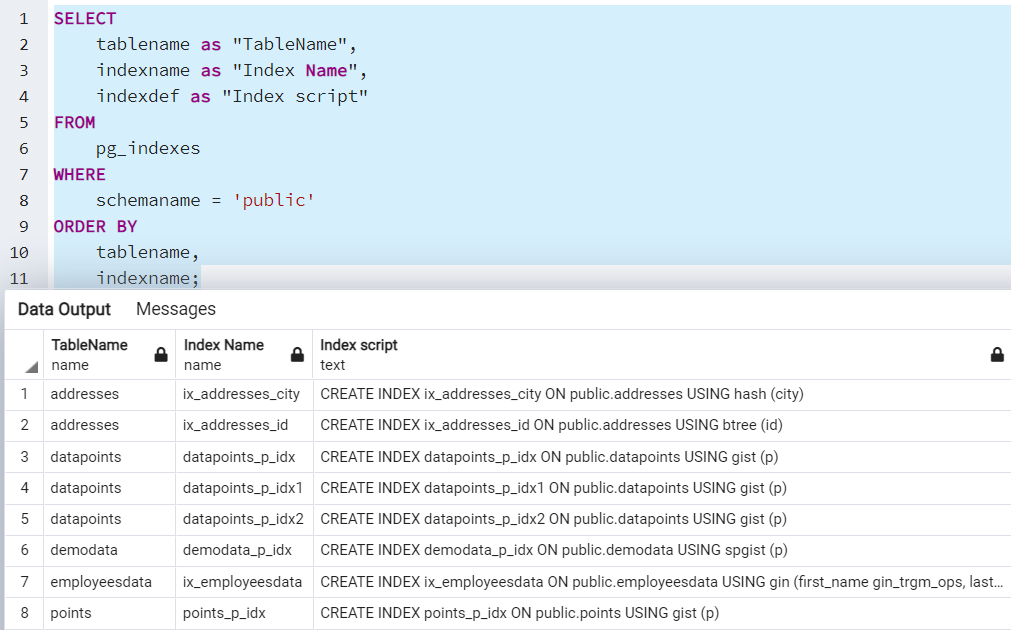
List indexes in Postgres
Suppose you require a list of indexes for all objects in a specific schema or a particular table. For this purpose, we can use the pg_indexes view. It returns the index definition as well the index. In the below query, it returns index information for all tables in the public schema.
SELECT tablename as "TableName", indexname as "Index Name", indexdef as "Index script" FROM pg_indexes WHERE schemaname = 'public' ORDER BY tablename, indexname;
Important guidelines for Postgres indexes
- The default Postgres index is a B-tree index.
- You should always properly analyze your workload using query execution plans to determine the suitable Postgres index type.
- Always create indexes on the most executed and costly queries. Avoid creating an index to satisfy a specific query.
- As per best practice, always define a primary or unique key in a Postgres table. It automatically creates the B-tree index.
- Avoid creating multiple indexes on a single column. It is better to look at which index is appropriate for your workload and drop the unnecessary indexes.
- There is no specific limit on the number of indexes in the table; however, try to create the minimum indexes satisfying your workload.


