

In this article, we will explore what a Postgres table is, its function and the various methods for creating tables in PostgreSQL.
PostgreSQL or Postgres is a popular relational, object-oriented and open source database system. It runs on Windows, Linux and Unix (AIX, BSD, HP-UX, macOS, Solaris) operating systems. Postgres supports Atomicity, Consistency, Isolation and Durability (ACID) properties.
To work within the database, you must create tables and store data within those tables. Relational databases organize tables in a row and column-level architecture.
Environment specifics
In this article, we’ll use PostgreSQL 13.1 version on the Windows platform. You can browse to EDB and download the latest edition on the platform of your choice.
Creating a Postgres table using the pgadmin4 graphical tool
To design a Postgres table, the following essential items are required:
- Source database
- Schema
- Required columns and their data types
- Index or keys
- Temporary or permanent table
Once you install Postgres 13 and connect it with the pgadmin4 tool, it shows a default database and its associated objects.
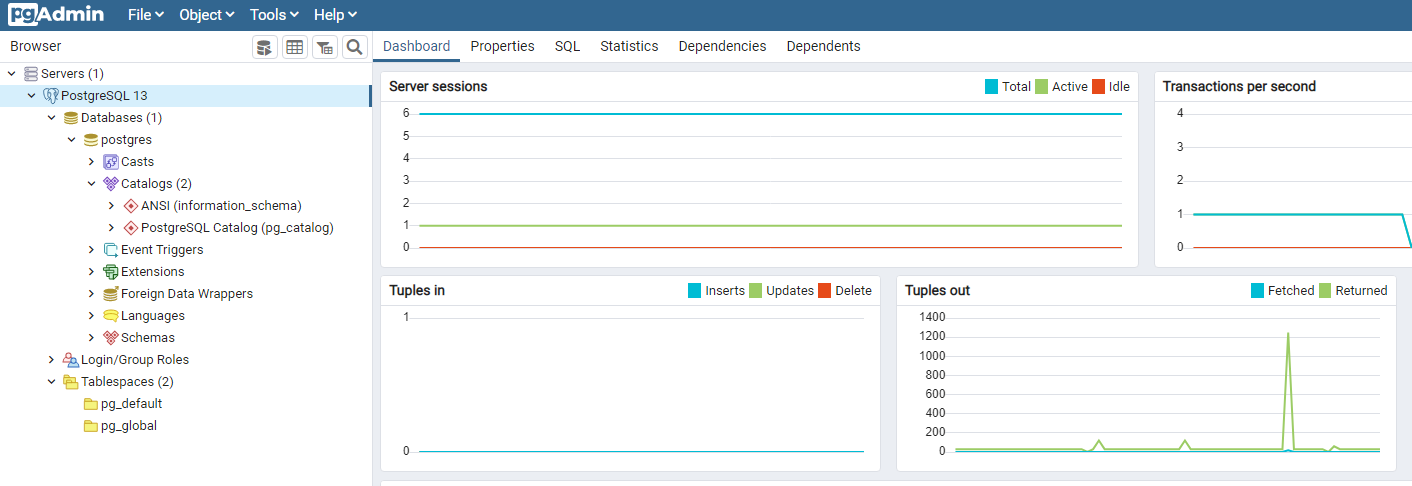
It is always recommended to use a user-defined database and schema for any objects created. The basic syntax for a new database table is shown below.
CREATE TABLE [IF NOT EXISTS] table_name ( column1 datatype(length) column_contraint, column2 datatype(length) column_contraint, …Column N datatype(length) column_contraint table_constraints );
Specify the table name after the CREATE TABLE statement. It should be a unique name in the database and schema.
- You can include an optional IF NOT EXISTS clause so that the table gets created if it does not exist with the same name.
- Further, specify the column names and their data types. You should also specify whether the column allows NULL values.
- You can also specify the constraints such as primary key, foreign key, unique or check constraints.
Understanding PostgreSQL data types
Postgres supports the following useful data types. You can refer to data types for a complete list and understanding of their usage.
- Boolean: This is used to declare a true or false value. For example, you can use a Boolean value to define an active or inactive employee flag. It takes one byte for storage.
- Character:
- Character varying(n), varchar(n): Variable-length character data.
- Character(n), char(n): Fixed length
- Text: Variable with unlimited length
- Numeric:
- Integers
- smallint: Range -32768 to +32767. Storage takes two bytes
- integer: Range -2147483648 to +2147483647. Storage takes four bytes
- bigint: Range -2^63 (-9223372036854775808) to 2^63 – 1(9223372036854775807). Storage takes eight bytes
- SmallSerial: Auto-increment integer range 1 to 32767
- Serial: Auto-increment integer range 1 to 2147483647
- Bigserial: Auto-increment integer 1 to 9223372036854775807
- Floating-point number
- Decimal and numeric: User-specified precision
- Real and double precision: Variable precision
- Geometric Types: Point, line, lseg, path, polygon and circle
- Network Address Types: inet, cidr,macaddr
- Integers
Let’s start creating Postgres tables.
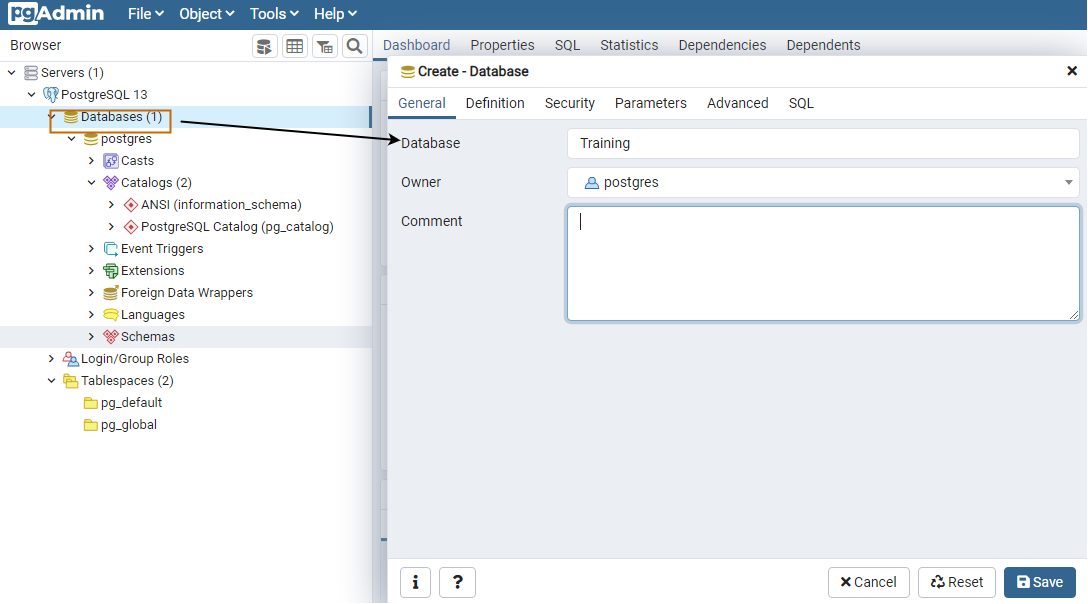
To satisfy the requirements stated above, we will create a new database called Training.
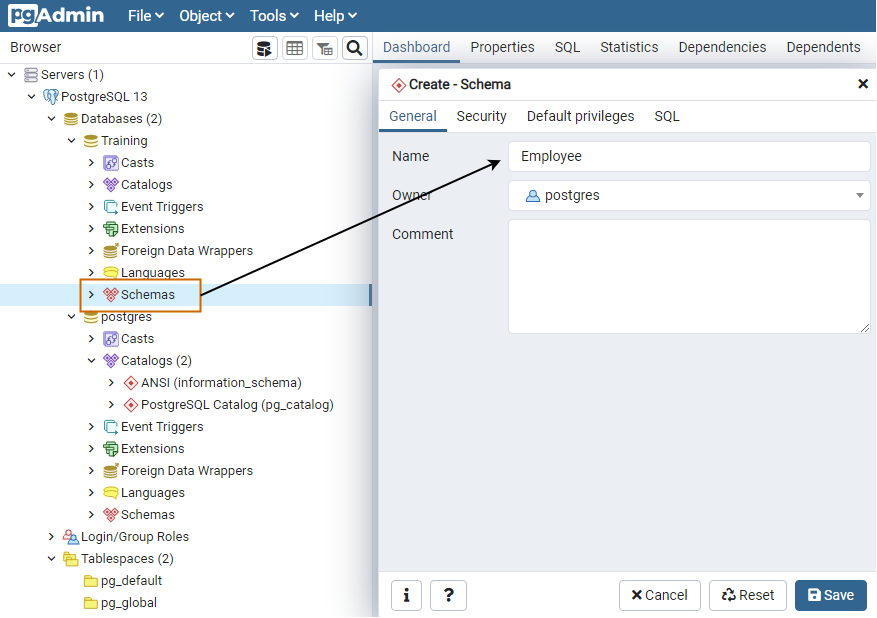
It is always advisable to use a specific schema for your database objects. Here, we use the [Employee] schema for our tables.
Expand your schema [Employee] and navigate to Tables -> Create -> Table.
Here, we will specify the following details:
- Name: The table name that you wish to create
- Owner: Table owner
- Schema: Select the table schema
- Tablespace: By default, a new table uses the pg_default tablespace
- Partitioned table: Leave it with the default option of No; we will cover it later
- Comment: It is an optional argument for reference purposes
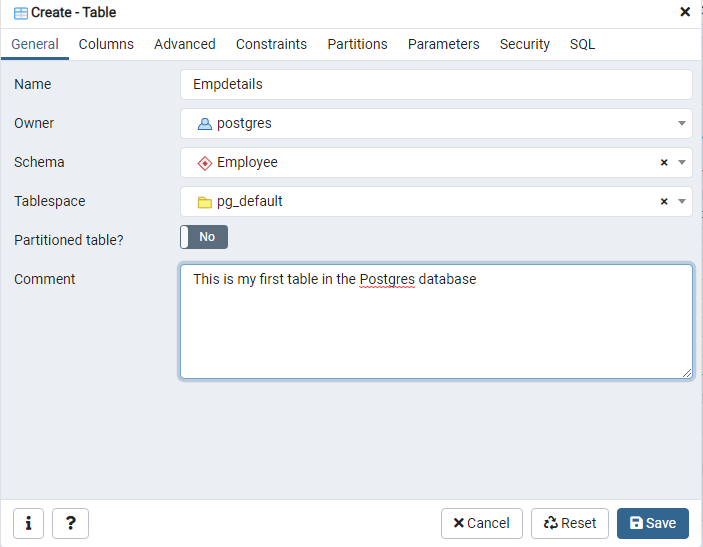
Next, click on the Columns tab. Here, we need to fill out the required table columns and their data types. I enabled the primary key for [EmpID] that defines the unique values in a column.
Note: As per best practice, you should create a primary key column in a table.
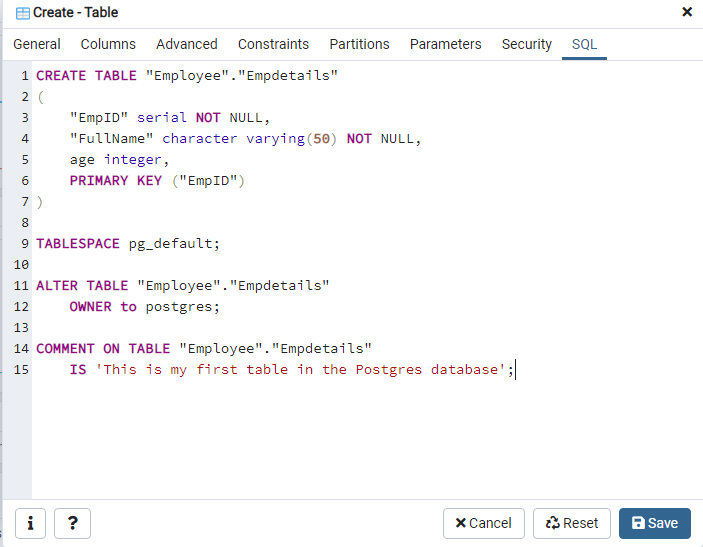
The pgadmin4 tool generates the SQL script for your graphical activity. It is an excellent way to learn SQL for Postgres. The generated script is shown below for a permanent table.
CREATE TABLE “Employee”.”Empdetails” ( “EmpID” serial NOT NULL, “FullName” character varying(50) NOT NULL, age integer, PRIMARY KEY (“EmpID”) ) TABLESPACE pg_default; ALTER TABLE “Employee”.”Empdetails” OWNER to postgres; COMMENT ON TABLE “Employee”.”Empdetails” IS ‘This is my first table in the Postgres database’;
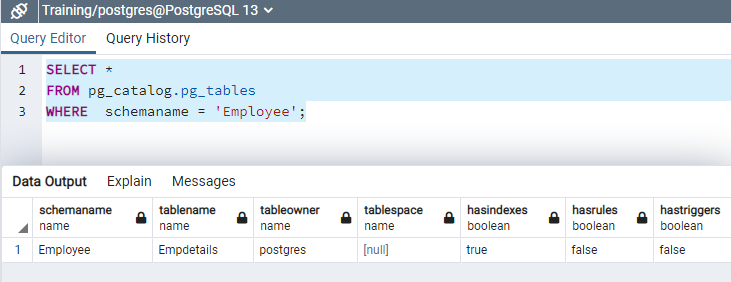
You can query pg_catalog for Postgres tables in a specific schema. For example, the below query lists tables in the [Employee] schema.
SELECT * FROM pg_catalog.pg_tables WHERE schemaname = 'Employee';
Creating temporary Postgres tables
By default, Postgres creates a permanent table that does not destroy your session. You can connect the database anytime, and it exists until you explicitly drop it.
The temporary table is useful for storing intermediate data. For example, in the complex query workflow, sometimes you need a table to store data temporarily. Postgres supports the temporary table that deletes automatically once your session terminates.
The SQL for creating a temporary table is identical with a small difference in comparison to the permanent table. You require a keyword Temporary or Temp for the temporary table, as shown below.
CREATE Temporary TABLE Tempdata1 ( "Salary" integer, empid serial );
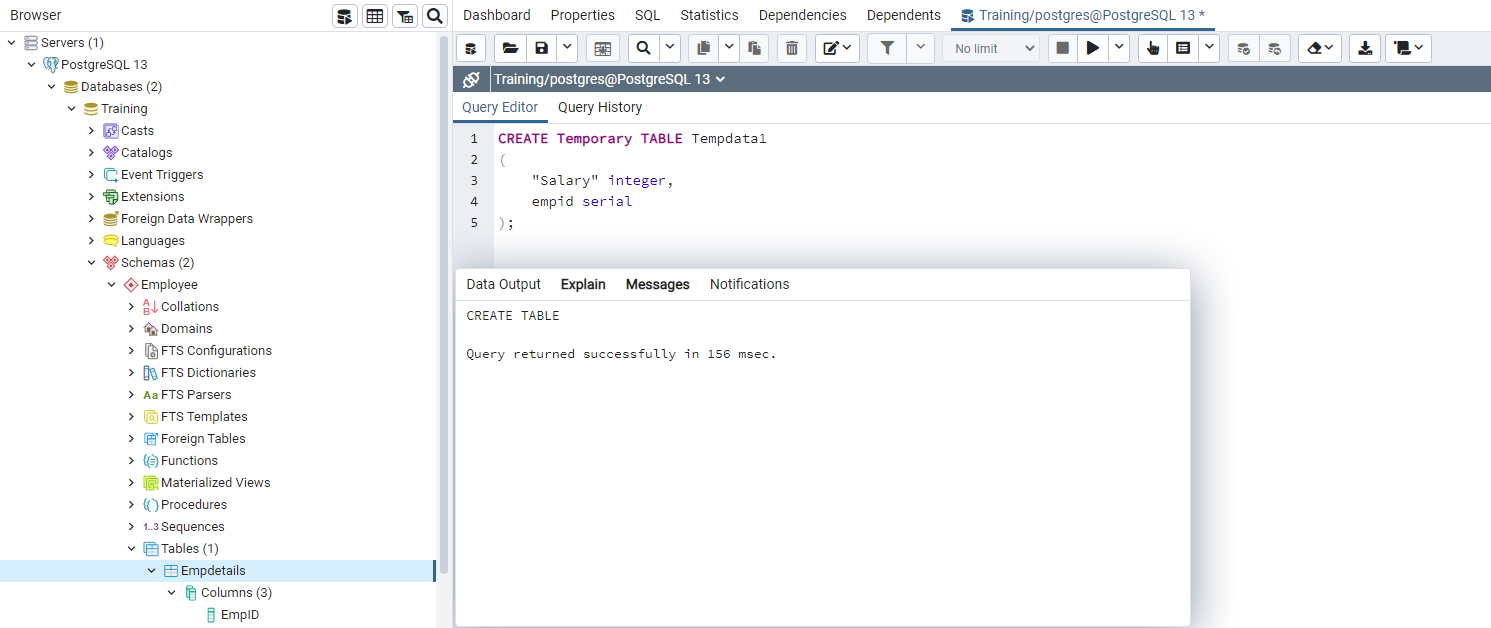
Important reminders about temporary Postgres tables:
- You cannot access the temporary table from another Postgres session.
- You cannot specify a user-defined schema for the temporary table because PostgreSQL creates temporary tables in a particular schema.
- The permanent and temporary tables can share the same name. However, it is not recommended to avoid confusion.
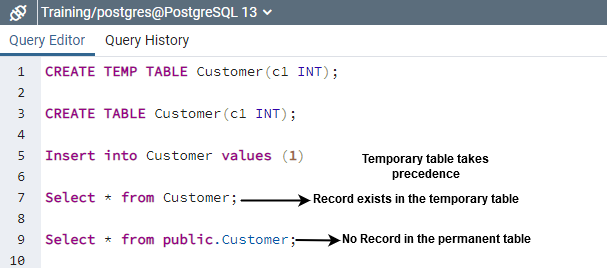
- For example, in below scripts, we created a permanent and temporary table named Customer in the same session.
- Later, it inserts a record in the Customer table. Into which table did it insert data – temporary or permanent?
CREATE TEMP TABLE Customer(c1 INT); CREATE TABLE Customer(c1 INT); Insert into Customer values (1)
By default, it inserts data into the temporary table if you have created any table in the specific session. Therefore, you should avoid using the same naming convention for both permanent and temporary Postgres tables.
Postgres table constrains
The constraints are a set of rules that you can apply for table columns. For example, if you do not want null values in a specific column, you can restrict that using constraints.
Supported constraints: NULL, UNIQUE, PRIMARY KEY, REFERENCES and CHECK()
- CHECK constraint: The CHECK constraint evaluates a Boolean expression and inserts and updates data if the expression evaluation is true. For example, the following query uses CHECK constraints:
- Employee birthdates should be greater than 1900-01-01
- Employee salary cannot be less than or equal to zero
CREATE TABLE employees ( id SERIAL PRIMARY KEY, "Name" VARCHAR (50), birthdate DATE CHECK (birthdate > '1900-01-01'), salary numeric CHECK(salary > 0) );
- UNIQUE constraint: We can specify the UNIQUE constraint to ensure the column values are unique across all rows. For example, two employees in an organization might have similar names, but their email ID should be unique.
CREATE TABLE employees ( id SERIAL PRIMARY KEY, "Name" VARCHAR (50), email varchar(100) UNIQUE );
- NOT NULL constraint: We can control the column behavior to accept NULL value using the NOT NULL constraint. For example, we cannot have an employee without a name. Therefore, we specify the NOT NULL to reject any query that tries to insert NULL in the [Name] column of the [Employees] table.
CREATE TABLE employees ( id SERIAL PRIMARY KEY, "Name" VARCHAR (50) NOT NULL, email varchar(100) UNIQUE );
- PRIMARY KEY constraint: The PRIMARY KEY constraint uniquely identifies a row in a database table. You can’t have more than one primary key in a table; however, it might span across multiple columns. For example, we use an ID column in the [employees] table.
CREATE TABLE employees ( id SERIAL PRIMARY KEY, "Name" VARCHAR (50) NOT NULL, email varchar(100) UNIQUE );
- FOREIGN KEY constraint: A FOREIGN KEY links two tables together in a relational database. In a table, the FOREIGN KEY references the PRIMARY KEY of another table.
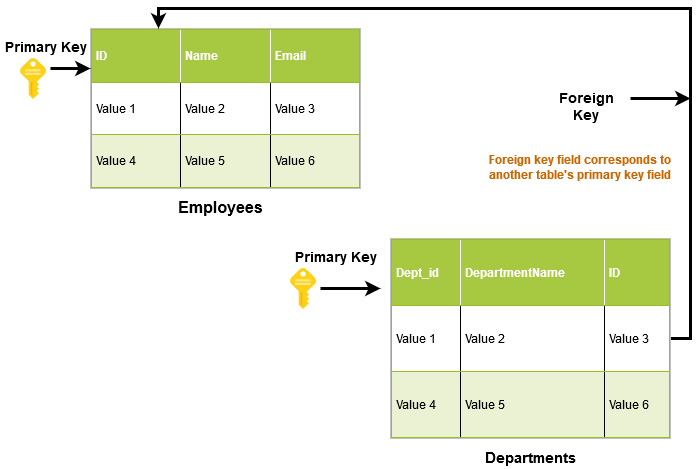
In the below script, we create a departments table that acts like a child table for the parent table [employees]. In the child table, we define a foreign key constraint that references the id column of [employee] table.
Create table departments ( dept_id SERIAL PRIMARY KEY, id serial, departmentname varchar(50), CONSTRAINT fk_customer FOREIGN KEY(id) REFERENCES employees(id) )
Modifying a table structure using the ALTER TABLE
The requirements might change for table columns, their data types or constraint after you design a table. For example, we might be required to add a new column, drop an existing column or change the column properties in an existing table. We would use ALTER TABLE to accomplish these actions:
- Add a column into an existing table
ALTER TABLE employees ADD COLUMN address VARCHAR(100);
- Drop the existing column
ALTER TABLE video DROP COLUMN address RESTRICT
- Rename the column
ALTER TABLE employees RENAME COLUMN departmentname To department
- Add a NOT NULL constraint to a column
ALTER TABLE employees ALTER COLUMN department SET NOT NULL;
- Move a table to a different schema
ALTER TABLE departments SET SCHEMA employees;
Using the Postgres DROP TABLE statement
You can use the DROP TABLE query to delete a table in Postgres. Once you drop a table, Postgres automatically drops the indexes and constraints as well. You should specify a schema name for objects to delete it, or it will drop the table from the default schema if a similar table name exists.
The following query drops a customer table from the default public schema.
drop table customer
The below query drops customer table from the [employees] schema.
drop table employees.customer
The importance of designing tables
A database table is an important entity in a relational database design. It defines the structure for storing your data and helps fetch information in a quick and efficient way. You must consider factors like PRIMARY, UNIQUE, FOREIGN KEYS, indexes, data types, normalizations and relationships before creating these tables.
We will cover these topics further in upcoming articles. Stay tuned!


